Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern
-
@Marc Berg
ich glaube das macht so keinen Sinn. Der Kopiert wohl noch 2 Tage ....
Ich merke gerade ich schreibe alle meine Datenpunkte nahezu pro Sekunde in die Influx.Ich glaube ich muss die DB neu aufbauen mit diesen Downsampling-Bucket:
https://forum.iobroker.net/topic/58462/datenaufzeichnung-retention-influxdb-2-0/21 -
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Ich merke gerade ich schreibe alle meine Datenpunkte nahezu pro Sekunde in die Influx.
Ja, das bricht wohl jeder Hardware irgendwann den Hals. Ich denke auch, in dieser Situation ist es das Beste, grundsätzlich neu anzufangen, die vorhandenen Daten aggregiert in ein anderes Bucket zu schreiben und sich zu überlegen, wie man schon ganz am Anfang die Datenflut begrenzen kann. Der Adapter bietet da ja einige Möglichkeiten.
-
Immerhin, wieder etwas gelernt.
Wenn ich den Datenpunkt in die Influx schreiben lasse gibt es die Option: Blockzeit
Verstehe ich das richtig, dass ich hier 5 Min einstellen könnte und er dann nur alle 5 Minuten einen Wert wegschreibt auch wenn es davon eine Veränderung gab?
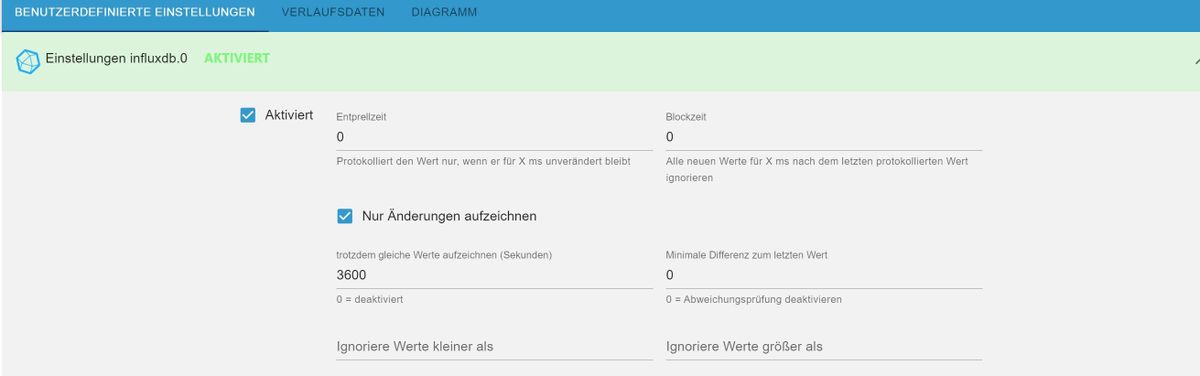
Damit könnte ich die Datenflut auch etwas eingrenzen.
-
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Verstehe ich das richtig, dass ich hier 5 Min einstellen könnte und er dann nur alle 5 Minuten einen Wert wegschreibt auch wenn es davon eine Veränderung gab?
Das ist eine Möglichkeit, ja. Ich persönlich finde es besser, den Haken "Nur Änderungen aufzeichnen" zu setzen und zusätzlich ausschließlich die minimale Differenz (je nach Eingangsdaten) einzutragen. Damit kann ich z.B. Temperaturänderungen von kleiner 0.2K ausfiltern, bekomme aber trotzdem kurzfristige signifikante Schwankungen mit, die mir mit der Blockzeit ggf. verloren gingen. Das ist aber natürlich sehr von den Eingangsdaten abhängig.
-
Wenn ich ein neues Bucket anlege und den iobroker darauf umstelle, werden die measuremnts glaube automatisch neu erstellt und mit daten gefüllt.
Wenn ich dann vom alten Bucket 2,3 measuremnts mit dem Befehl rüber kopiere, bleiben dann die neuen Daten erhalten? also wir das hinzugefügt ?
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_measurement"] == "test") |> to(bucket: "iobroker_tmp") -
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Wenn ich ein neues Bucket anlege und den iobroker darauf umstelle, werden die measuremnts glaube automatisch neu erstellt und mit daten gefüllt.
ja
Wenn ich dann vom alten Bucket 2,3 measuremnts mit dem Befehl rüber kopiere, bleiben dann die neuen Daten erhalten? also wir das hinzugefügt ?
ja, da geht nichts verloren.
-
Weißt du zufällig ob ich das Delete-alter eines Buckets auch nachträglich ändern kann?
ZB: ich stelle es jetzt auf 1 Jahr und nach ein paar Monaten auf 6 Monate ?Oder muss ich dann das Bucket umbenennen, ein neues anlagen und die Daten rüber schieben?
Sorry, habe gerade gesehen das es in den Settings einzustellen geht ....
-
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Sorry, habe gerade gesehen das es in den Settings einzustellen geht ....
Genau, oder auch über die Instanzeinstellungen des Adapters.
-
zu dem Script, verstehe ich das richtig:
import "timezone" option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} option location = timezone.location(name: "Europe/Berlin") data = from(bucket: "ioBroker") |> range(start: -2mo, stop: now()) |> filter(fn: (r) => r["_measurement"] == "Vb_Stromzaehler") |> filter(fn: (r) => r["from"] == "system.adapter.javascript.0") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "RBE")Was bedeutet:
name: "Downsampling Vb_Stromzaehler"
Ist das frei wählbar oder ein Bucket / Measurement ?range(start: -2mo, stop: now())
Wenn das Script täglich läuft müsste doch auch -1d reichen weil er doch dann regelmäßig wegschreibt oder warum macht er hier -2mo ?|> filter(fn: (r) => r["_measurement"] == "Vb_Stromzaehler")
|> filter(fn: (r) => r["from"] == "system.adapter.javascript.0")
er filtert nach measurement aber warum dann noch das from ?
ich habe hier immer: |> filter(fn: (r) => r["_field"] == "value")|> set(key: "_measurement", value: "Hauptzaehler")
|> to(bucket: "Stromverbrauch", org: "RBE")
das heißt es wird in das bucket Stromverbrauch mit _measurement "Hauptzaehler" geschrieben oder ? -
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Was bedeutet:
name: "Downsampling Vb_Stromzaehler"
Ist das frei wählbar oder ein Bucket / Measurement ?Lege über die Oberfläche einfach mal einen neuen Task an. Dann siehst du, dass die Eingaben aus der Gui übernommen werden. Dies ist also einfach nur ein Name, der beliebig sein kann.
range(start: -2mo, stop: now())
Wenn das Script täglich läuft müsste doch auch -1d reichen weil er doch dann regelmäßig wegschreibt oder warum macht er hier -2mo ?Wenn das Skript aus welchen Gründen auch immer mal nicht laufen sollte, ist es besser ein paar Tage weiter in die Vergangenheit zu gehen. Bei einem Job, der Tagesdaten zusammenstellt, wären 2 Monate wohl zu viel.
Aber darauf achten, dass auch ein "stop" angegeben werden muss, sonst holst du die angebrochenen Tage, an welchem der Task läuft mit rein. Steht hier im Thread weiter oben, wie das geht.|> set(key: "_measurement", value: "Hauptzaehler")
|> to(bucket: "Stromverbrauch", org: "RBE")
das heißt es wird in das bucket Stromverbrauch mit _measurement "Hauptzaehler" geschrieben oder ?genau, ist natürlich frei wählbar.
-
du meinst so:
|> range(start: -2mo, stop: date.truncate(t:-1s, unit:1mo)Jetzt verstehe ich deine Aussage und dann das Problem.
Ich wollen mit " stop: now()) " arbeiten und den Task alle 30 Minuten laufen lassen.
Dann hätte ich in der Grafana Abfrage auch immer auch den aktuellen Tag mit drin.Dumm aber das ich dann pro Stunde 2 Werte schreibe.
So ein Mist, immer ein neues Problem
-
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
|> range(start: -2mo, stop: date.truncate(t:-1s, unit:1mo)
in diesem Beispiel würde JETZT (11.01.24 14:00) die Abfrage vom 12.12.23 14:00 bis 01.01.24 00:00 Uhr laufen. Das bedeutet, dass du auch für den Startzeitpunkt mit "truncate" arbeiten musst und statt des Monats den Tag nehmen musst, um ganze Tage bis gestern zu erfassen.
|> range(start: date.truncate(t:-3d, unit:1d), stop: date.truncate(t:-1s, unit:1d))das bedeutet JETZT: vom 08.01.24 00:00 Uhr bis 11.01.24 00:00 Uhr
-
@Marc Berg
OK, baue ich gleich um.
In deinem Beispiel ist -3d.Wenn ich das Script jetzt täglich ausführe und heute starte:
schreibt er am 11.01
Tageswert 11.1
Tageswert 10.1
Tageswert 09.1schreibt er am 12.01
Tageswert 12.1
Tageswert 11.1
Tageswert 10.1Ist dann der Tageswert vom 10.1, bzw. 11.11 doppelt vorhanden (zwei Einträge in der DB) oder "überschreibt" er den bestehenden?
-
Hallo Marc.
Ich bin noch immer an dem Umbau und möchte jetzt ein measuremnt das über 100K Einträge hat etwas ausdünnen.
Ich arbeiten im Influx Data Explorer.
Was passte denn an diesem Syntax nicht?from(bucket: "iobroker-unlimited") |> range(start: -36mo, stop: -2mo) |> filter(fn: (r) => r._measurement == "Strom-IR-Haus-Bezug") |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") |> toInt() |> set(key: "_measurement", value: "TEST-Strom-IR-Haus-Bezug") |> to(bucket: "iobroker-unlimited")Fehler:
runtime error @5:8-5:15: toInt: failed to evaluate map function: cannot convert string "system.adapter.sonoff.0" to int due to invalid syntax -
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Was passte denn an diesem Syntax nicht?
Dir fehlt der Filter auf die Spalte "value", sonst bekommst du wahrscheinlich auch die internen Spalten "q" "ack" und "from" mit, wenn die Daten aus dem Adapter kommen.
from(bucket: "iobroker-unlimited") |> range(start: -36mo, stop: -2mo) |> filter(fn: (r) => r._measurement == "Strom-IR-Haus-Bezug") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") |> toInt() |> set(key: "_measurement", value: "TEST-Strom-IR-Haus-Bezug") |> to(bucket: "iobroker-unlimited") -
Er legt mir das neue measurement an, aber wenn ich im Data Explorer bin fehlt bei field "value"
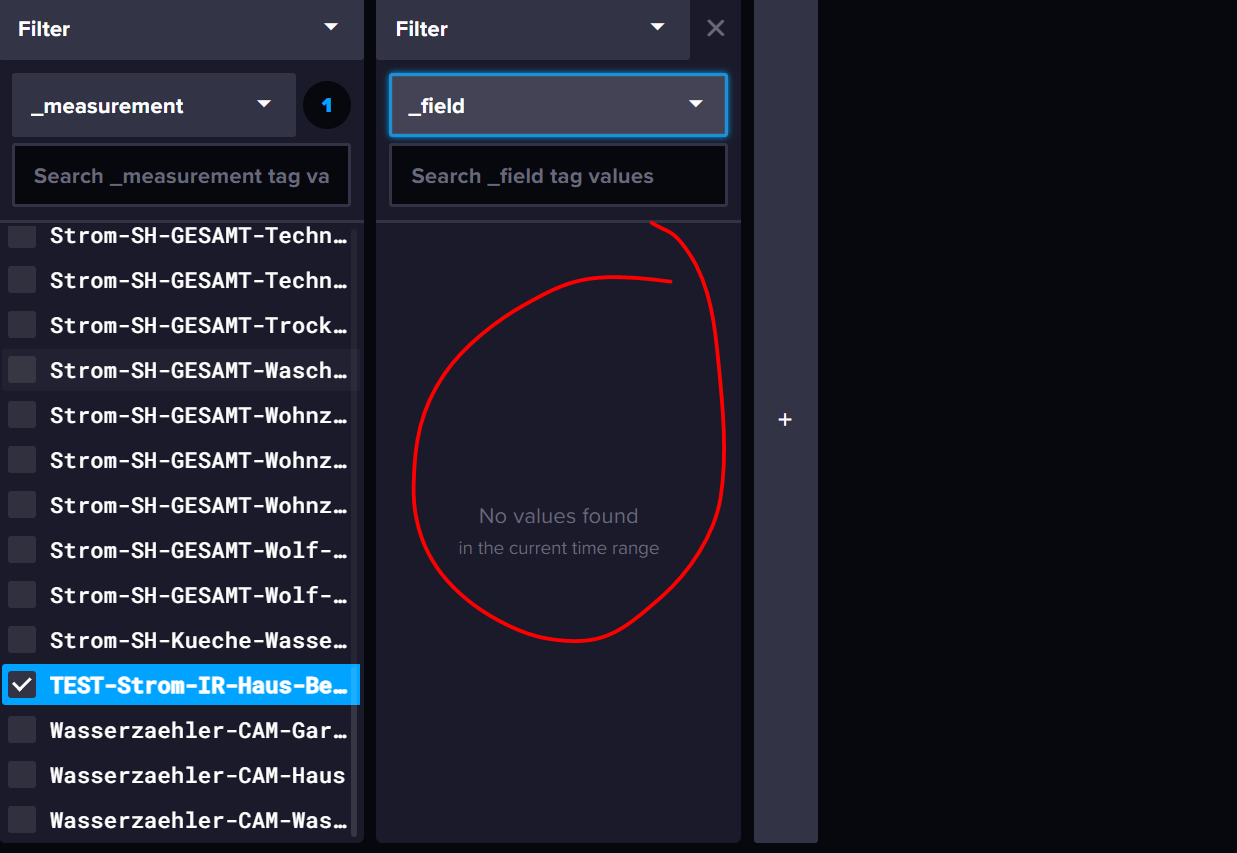
Im Grafana kann ich die Daten aber anzeigen lassen.
Warum fehlen denn im Dataexplorer die Felder ? -
@bitwicht sagte in [Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern]
Warum fehlen denn im Dataexplorer die Felder ?
Wahrscheinlich hast du den Zeitraum nicht groß genug gewählt.
-
stimmt
")
Das heißt ich kopiere jetzt das original-measuremnt in ein measuremnt -TEMP
dann vom TEMP die Dante von XX bis 31.12.2023 aggregiert zurück in das original-measuremnt
und dann von 1.1.2024 bis heute zurück in das original-measuremntdieganz schöner Aufwand.
Gibt es nicht ein Befehl der von XX bis YY nur den einen Wert pro Tag stehen lässt und alles andere weghaut ?
-
delete.......
-
deleteeeee
