Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern
-
du meinst so:
|> range(start: -2mo, stop: date.truncate(t:-1s, unit:1mo)Jetzt verstehe ich deine Aussage und dann das Problem.
Ich wollen mit " stop: now()) " arbeiten und den Task alle 30 Minuten laufen lassen.
Dann hätte ich in der Grafana Abfrage auch immer auch den aktuellen Tag mit drin.Dumm aber das ich dann pro Stunde 2 Werte schreibe.
So ein Mist, immer ein neues Problem
-
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
|> range(start: -2mo, stop: date.truncate(t:-1s, unit:1mo)
in diesem Beispiel würde JETZT (11.01.24 14:00) die Abfrage vom 12.12.23 14:00 bis 01.01.24 00:00 Uhr laufen. Das bedeutet, dass du auch für den Startzeitpunkt mit "truncate" arbeiten musst und statt des Monats den Tag nehmen musst, um ganze Tage bis gestern zu erfassen.
|> range(start: date.truncate(t:-3d, unit:1d), stop: date.truncate(t:-1s, unit:1d))das bedeutet JETZT: vom 08.01.24 00:00 Uhr bis 11.01.24 00:00 Uhr
-
@Marc Berg
OK, baue ich gleich um.
In deinem Beispiel ist -3d.Wenn ich das Script jetzt täglich ausführe und heute starte:
schreibt er am 11.01
Tageswert 11.1
Tageswert 10.1
Tageswert 09.1schreibt er am 12.01
Tageswert 12.1
Tageswert 11.1
Tageswert 10.1Ist dann der Tageswert vom 10.1, bzw. 11.11 doppelt vorhanden (zwei Einträge in der DB) oder "überschreibt" er den bestehenden?
-
Hallo Marc.
Ich bin noch immer an dem Umbau und möchte jetzt ein measuremnt das über 100K Einträge hat etwas ausdünnen.
Ich arbeiten im Influx Data Explorer.
Was passte denn an diesem Syntax nicht?from(bucket: "iobroker-unlimited") |> range(start: -36mo, stop: -2mo) |> filter(fn: (r) => r._measurement == "Strom-IR-Haus-Bezug") |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") |> toInt() |> set(key: "_measurement", value: "TEST-Strom-IR-Haus-Bezug") |> to(bucket: "iobroker-unlimited")Fehler:
runtime error @5:8-5:15: toInt: failed to evaluate map function: cannot convert string "system.adapter.sonoff.0" to int due to invalid syntax -
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Was passte denn an diesem Syntax nicht?
Dir fehlt der Filter auf die Spalte "value", sonst bekommst du wahrscheinlich auch die internen Spalten "q" "ack" und "from" mit, wenn die Daten aus dem Adapter kommen.
from(bucket: "iobroker-unlimited") |> range(start: -36mo, stop: -2mo) |> filter(fn: (r) => r._measurement == "Strom-IR-Haus-Bezug") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start") |> toInt() |> set(key: "_measurement", value: "TEST-Strom-IR-Haus-Bezug") |> to(bucket: "iobroker-unlimited") -
Er legt mir das neue measurement an, aber wenn ich im Data Explorer bin fehlt bei field "value"
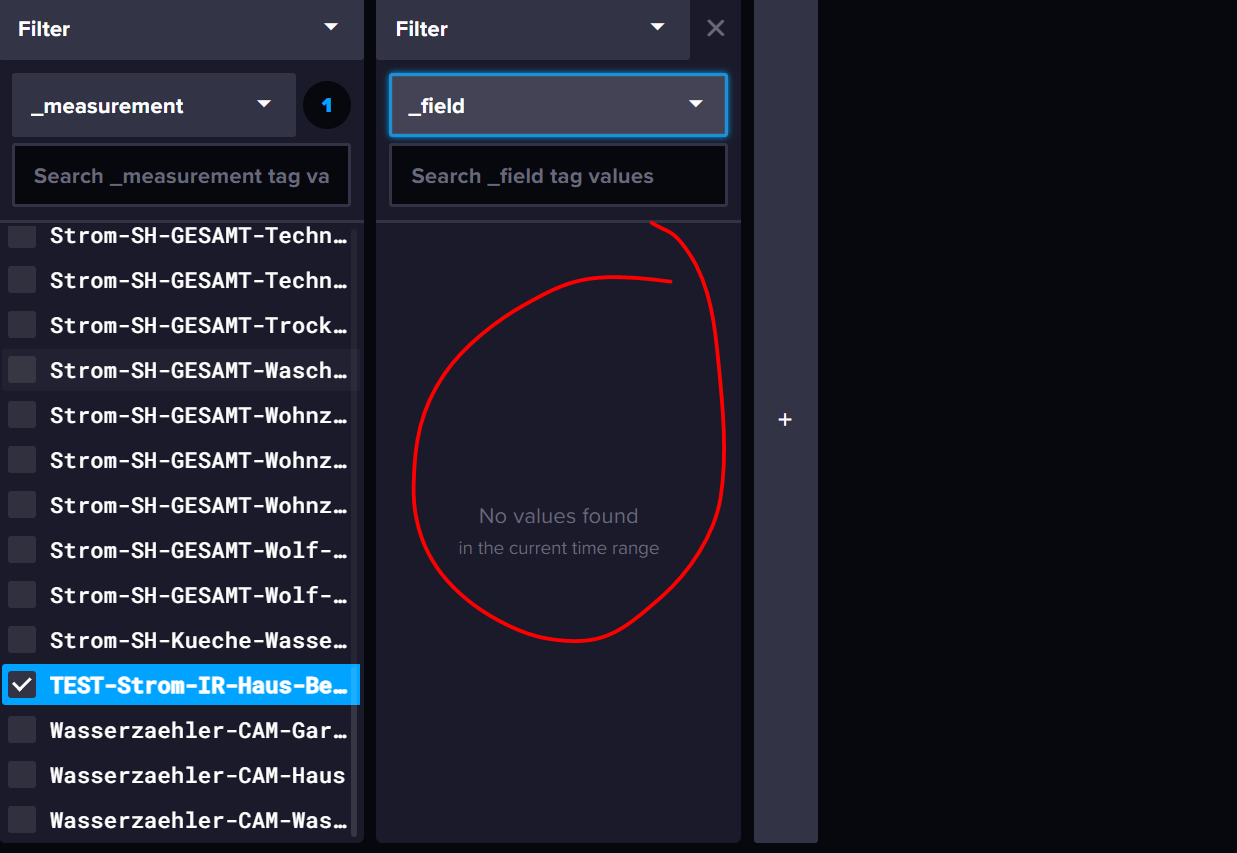
Im Grafana kann ich die Daten aber anzeigen lassen.
Warum fehlen denn im Dataexplorer die Felder ? -
@bitwicht sagte in [Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern]
Warum fehlen denn im Dataexplorer die Felder ?
Wahrscheinlich hast du den Zeitraum nicht groß genug gewählt.
-
stimmt
")
Das heißt ich kopiere jetzt das original-measuremnt in ein measuremnt -TEMP
dann vom TEMP die Dante von XX bis 31.12.2023 aggregiert zurück in das original-measuremnt
und dann von 1.1.2024 bis heute zurück in das original-measuremntdieganz schöner Aufwand.
Gibt es nicht ein Befehl der von XX bis YY nur den einen Wert pro Tag stehen lässt und alles andere weghaut ?
-
delete.......
-
deleteeeee
-
Ich versuche jetzt gerade in das neu angelegte Bucket die Historischen Werte einzutragen (was im alten Bucket nicht ging).
Manueller Import
Einstellung: SekundenPV_SE_Erzeugung_Monat_Adapter value="374000" 1706740200Wenn ich dann eine Abfrage auf das Measuremnt mache um wir die Werte anzeigen zu lassen kommt immer der Fehler:
unsupported input type for mean aggregate: stringWas mache ich denn beim Import falsch?
-
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Was mache ich denn beim Import falsch?
Du wirst in deiner (wahrscheinlich automatisch erstellen) Abfrage ein "aggregateWindow" drin haben, was auf einer Spalte, die nicht vom Typ "number" ist, nicht funktioniert. Wenn du den Wert in " setzt, wird daraus automatisch ein String.
-
Passt, das wars. Danke.
-
Ich habe die Daten (ca. 12 Monate) dann so eingegeben ohne Problem:
PV_SE_Erzeugung_Monat_Adapter value=374000 1706740200Nach weiterer Eingabe von ca. 12 Monaten kommt jetzt dieser Fehler:
panic: runtime error: invalid memory address or nil pointer dereferenceIch habe jetzt das komplette measuremnt gelöscht und neu angelegt, jetzt scheint es zu gehen
-
Hast du hier noch eine Idee:
Ich gebe diesen Unix Zeit ein:
1669761000Das ist laut Rechner der: Your Time Zone Tue Nov 29 2022 23:30:00 GMT+0100 (Mitteleuropäische Normalzeit)
In der Influx wird es aber als
2022-12-02T20:48:00.000Zeingetragen
-
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
Hast du hier noch eine Idee:
Ich kann mir jetzt nicht vorstellen, dass die InfluxDB aus diesem Timestamp ein falsches Datum macht.
Und aus diesen zwei "Schnipseln" ist das für mich auch nicht wirklich "beweisbar". -
hier mein Import:
PV_SE_Erzeugung_Jahr_Adapter value=21300000 1703975400 (30.12.2023) PV_SE_Erzeugung_Jahr_Adapter value=23200000 1672439400 (30.12.2022) PV_SE_Erzeugung_Jahr_Adapter value=21800000 1640903400 (30.12.2021)und was dann in der DB steht:
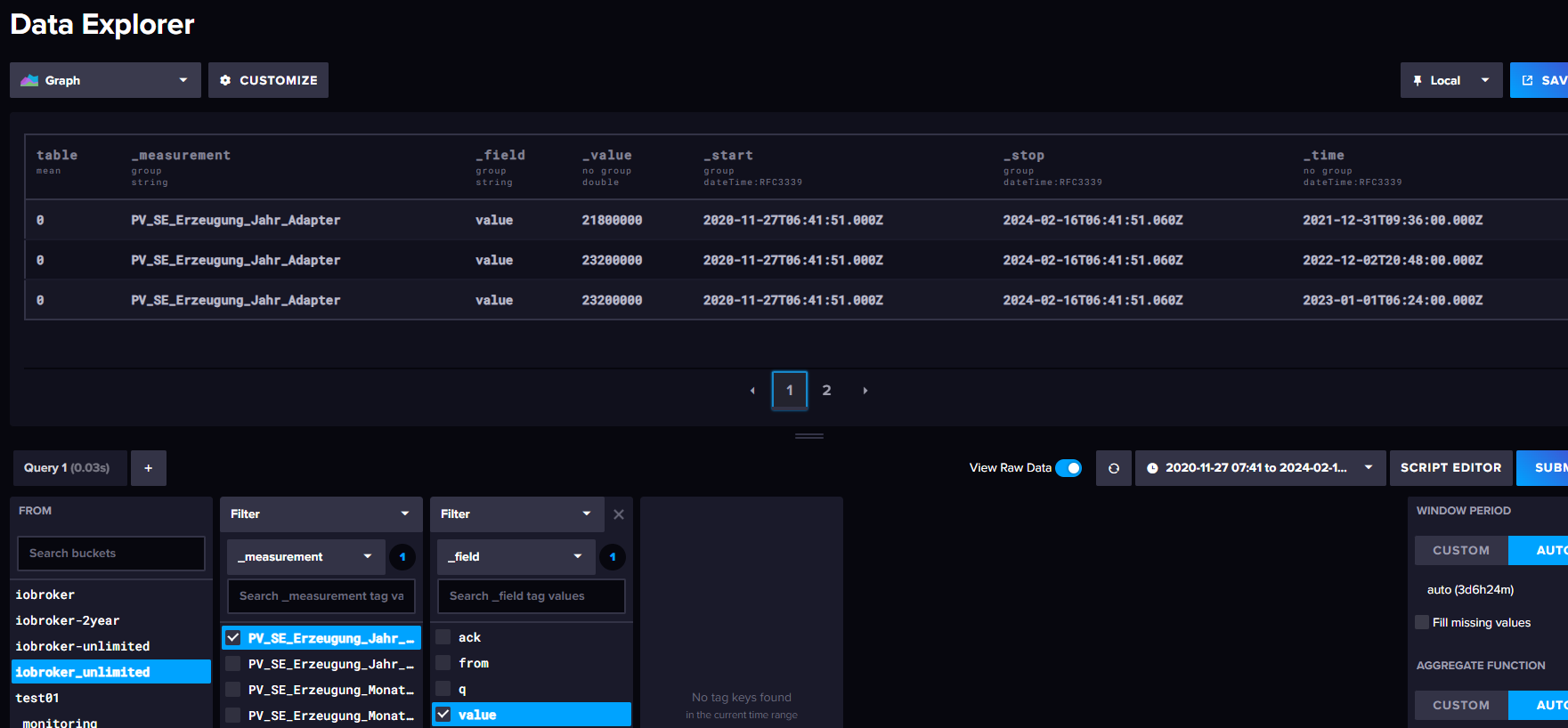
Die Zeit auf dem System passt:
Fri 16 Feb 11:34:52 CET 2024 -
-
from(bucket: "iobroker_unlimited") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "PV_SE_Erzeugung_Jahr_Adapter") |> filter(fn: (r) => r["_field"] == "value") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")Ohne
import "timezone" option location = timezone.location(name: "Europe/Berlin") -
@bitwicht sagte in Ertrag (Tag, Monat, Jahr) berechnen und in Datei speichern:
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
diese Zeile rausnehmen. Damit werden doch andere Zeitfenster gebildet.