Hoher CPU-Load des Raspberry
-
Nochmal ne Nachträgliche Beobachtung:
Hatte ne zeitlang das Problem das Adapter dauernd neugestartet wurden…dieses hat den load des RasPi in die Dekce getrieben...also:
-
log prüfen
-
redis nutzen.
Momentan ideln meine RasPis so bei load 0.2
bis denne
Mr.Lee
-
-
Hallo,
ich hänge mich hier dran, weil ich denke mein Problem passt ganz gut in diesen Thread.
Habe hier http://forum.iobroker.net/viewtopic.php?f=8&t=10145 mit hormorans Hilfe mein multihostproblem in den Griff bekommen (zumindest läuft der Slave stabil, wenn er auch noch nix zu tun hat)
Dabei fiel mir auf dass ich zur Zeit wieder verstärkt CPULoad-Spitzen habe. Ich hatte das erst mit dem Javascript-Adapter in Verbindung gebracht, hat sich aber nicht bestätigt.
Nun dass was ich beobachte: Sobald ich vis öffne und an meinen Seiten rumschraube kann ich beobachten, wie der Load Wert durch die Decke geht:
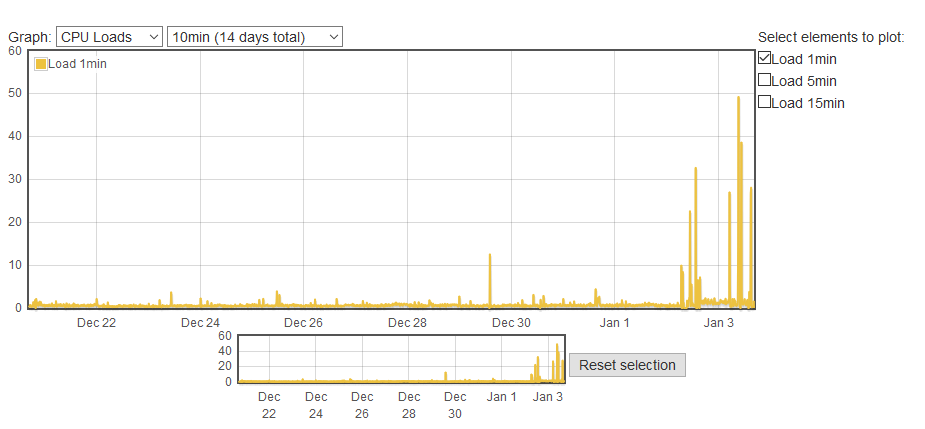
Dann wird das System komplett unbedienbar, und nach ca. 20min hat sich der Load Wert wieder auf ein erträgliches Mass eingepegelt (unter 1,0)Einzig der ping geht noch.
Gruß
crepp
Hier mal noch eine grössere Version: (aktuell geht gar nix mehr…)
-
Vis (und insbesondere iframes mit flot-charts) zehren schon an der Leistung des Pi.
wenn es bei dir aber eben diese flot Chrts sind, wird es weniger die CPU-Auslastung sein (was zu prüfen wäre), sondern die Schreib- und Lesezugriffe auf die Daten.
Was für eine SD-Karte hast du denn?
Gruß
Rainer
-
Sandisk,
Ich setzt die flotcharts aber seit mehr als einem Jahr ein von daher hat sich auf der Schiene nichts geändert. Und wenn man sich im moni die Historie anschaut, sieht man dass sich das Problem in den letzten Tagen (wieder) verstärkt hat.
Im logfile sind keine Fehler zu sehen, ausser dass ich sehe dass ab und zu sämtliche adapter neu gestartet werden (ohne Reboot)
-
Naja, um nicht raten zu müssen was da passiert schlage ich vor du machst eine SSH Shell auf und lässt dort "top" laufen. Dann provozierst Du den Fehler.
Was siehst Du in Top? geht die CPU Last eines prozesses hoch? Bei solch hohen CPU werten tippe ich eher darauf das der Raspi ins Swap geht weil ein Prozess mehr speicher braucht als Du hast … Aber das siehst Du damit.
Danach weisst Du aber auch welcher prozess es ist und man kann weiter überlegen
-
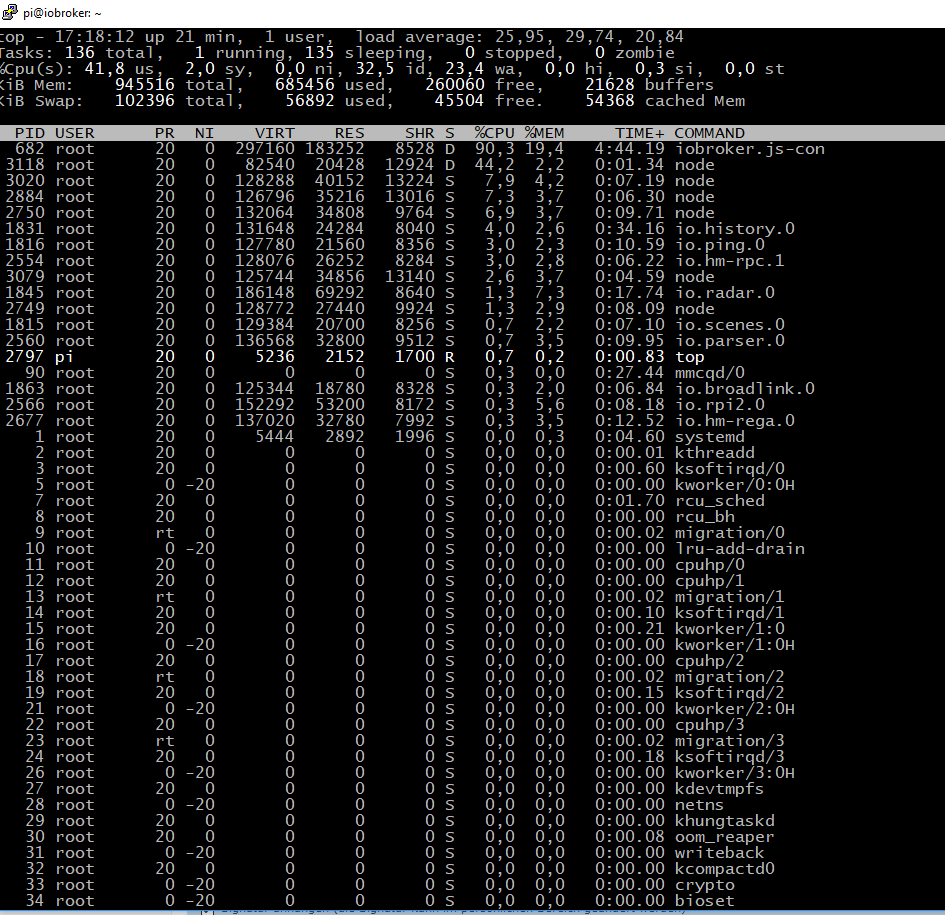
Naja den Fehler provozieren brauche ich nicht, habe jetzt beim pi den Stecker gezogen und nach dem reboot ca. 10min htop laufen gehabt.
Die Load Werte gehen nicht unter 8. D.h. über admin brauch ichs gar nicht zu versuchen. Bei solch hohem Load Werten läuft selbst htop nicht all zu lange.
-
Ändert sich der "Swap used" wert? Weil die CPU hat noch >30% idle, also ist es (ist Dual-Core Prozessor, oder ?!) eher ein Speicherproblem …
Sortiere die Prozessliste mal nach Speicherverbrauch
-
Wie vermutet hat die CPU noch reserve.
Das System swapped, wie apollon vermutet hat, und ide ganzen node - Prozesse deuten darauf hin, dass das System gar nicht erst in die Hufe kommt. Bei einem load von über 20 auch kein Wunder.
Vielleicht solltest du mal die Karte tauschen.
@crepp:habe jetzt beim pi den Stecker gezogen `
Das tötet Karten!
@crepp:und nach dem reboot `
Stecker ziehen ist kein reboot.Gruß
Rainer
-
Ja ich weiss schon, aber wenn ich fast ne viertelstunde nicht das System rankomme ?
Hab noch ne 2. Karte aber die ist ein paar bytes kleiner als diese hier, da muss ich erst mal ein kpl. Backup machen. Dann werde ich sie tauschen und wieder berichten. Swap used werde ich auch mal im Auge behalten. Momentan hat sich das System wieder beruhigt (wie auch immer ?!) Kann sogar wieder im vis arbeiten…
Vielen Dank vorläufig für Eure schnelle Hilfe !
-
Dann sieh dir mal die logs zu den Zeiten an, wenn es hakt.
ggf. läuft da ein Skript amok.
Gruß
Rainer
-
Wenn es wirklich ein Swap-Problem ist dann gibt es meistens einen OPunkt wo das OS den verursachenden Prozess killt.
Schau mal ob du sowas im "/var/log/syslog" findest. Ich galueb der Begriff ist "OOMKiller" oder so
-
Also wenn ich mir den top-screen anschaue fallen mir folgende Diege ein:
-
CPUs sind mit <50% beschäftigt, das ist nicht das Problem, Raspi's mit 1GB mem haben 4 CPU's also ist da Luft nach oben.
-
Wenn das nach einem re-boot war sind noch immer nicht alle Adapter voll geladen ('node'-Zeilen werden in Adapter-Instanzen umgewandelt wenn sie fertig sind mit dem Start)
-
Es sollte kein Swap nach dem re-boot verwendet werden, hatte ich noch NIE, nur nachdem ich eventuell neue Adapter installiere oder sonstige updates durchführe!
Ich würde ein
sudo iobroker stop sudo iobroker upgrade self sudo iobroker startdurchführen, nach dem Stop alle node-Prozesse entfernen wenn noch welche da sind.
-
-
@fsjoke
Kein Update
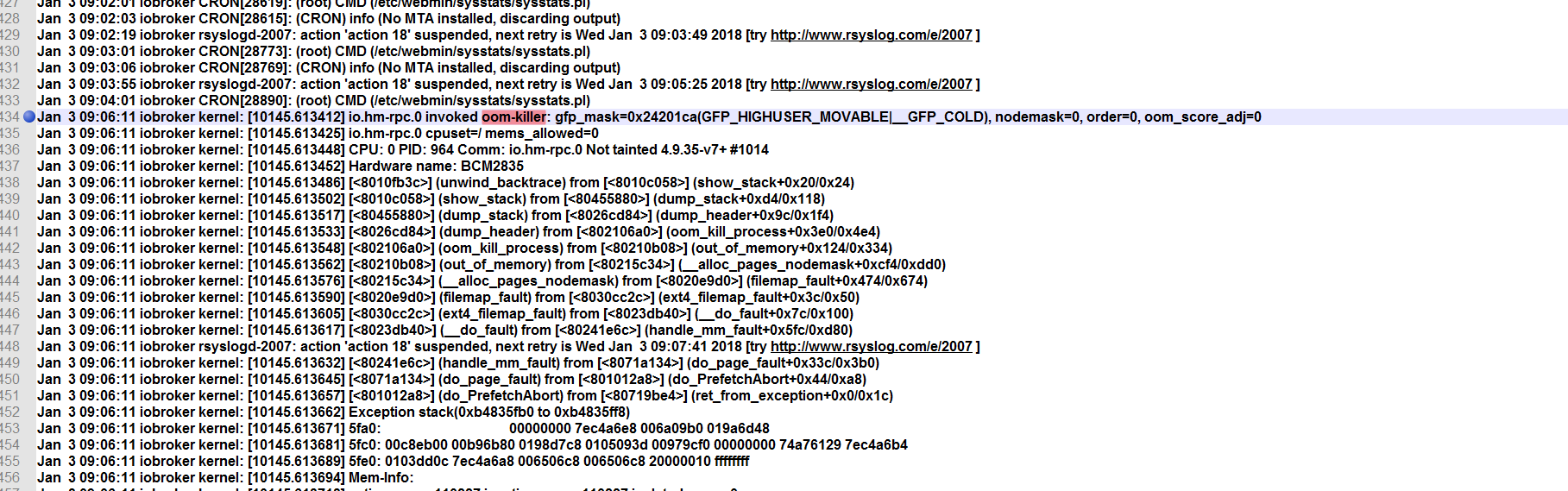
Habe das syslog von gestern mal durchgeforstet. Insgesamt 17 Fundstellen dieses Begriffs. Heisst das jetzt das das Problem mit dem Swapping zusammenhängt ?
686_update.png
686_oom-killer.png -
Ich habe jetzt nicht direkt eine Lösung für Dein Problem.
Aber ich hatte genau das selbe Verhalten wie Du es beschreibst. Mehrere Minuten kein Zugriff auf das System. System kommt nach Neustart nicht auf die Füße. Arbeiten in VIS System hängt sich auf, etc. Ich hatte einen Rasperry PI 3 im Einsatz.
Ich habe dann auf Multihost umgeschwenkt. Habe auf dem Master alle notwendigen Adapter (REGA, RPC, Admin, etc ist beschrieben im Beitrag siehe Link), alle anderen auf dem Slave. Vorallem der javascript Adapter hat bei mir viele Ressourcen gebraucht.
http://forum.iobroker.net/viewtopic.php?f=8&t=9534
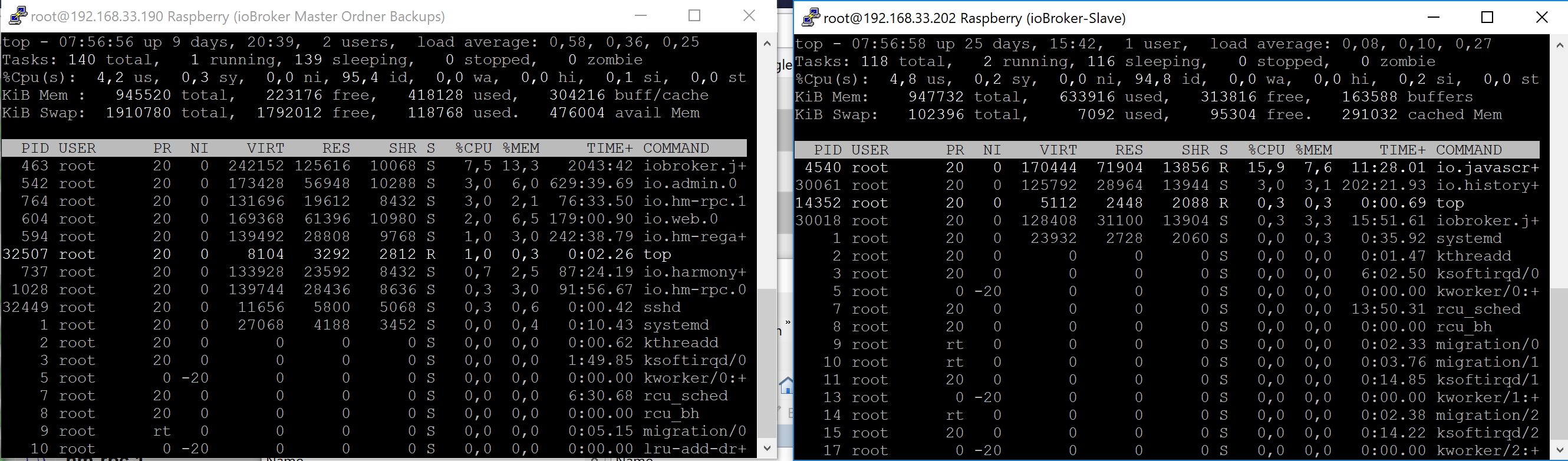
Die geringere Uptime vom Master ist vorhanden, da ich das System runtergefahren hatte um auf einen zweiten Master (Master Restore) den ich noch habe als Sicherung, ein Backup eingespielt habe. Die Uptime vom Slave wäre auch höher, da ist ein Stromausfall dazwischen gekommen.Seitdem ich die Aufteilung gemacht habe, laufen die Kisten ohne Probleme super stabil. Kein Vergleich zu vorher. Dabei ist Redis noch nicht mal aktiv, da ich mit der Sicherung der States in Redis noch auf Kriegsfuß stehe.
Solltest Dir vielleicht Gedanken machen ob Du bereit bist in einen zweiten Raspi zu investieren. Bei mir hat es sich auf jeden Fall richtig gelohnt
Gruß Zippolighter
-
Ja danke für den Tip, das habe ich auch schon vorbereitet. Der Slave ist schon aktiv, bin nur noch nicht dazu gekommen da das jetzige Problem dazwischenkam. Hatte ich einem Beitrag weiter oben auch erwähnt.
-
Habe das syslog von gestern mal durchgeforstet. Insgesamt 17 Fundstellen dieses Begriffs. Heisst das jetzt das das Problem mit dem Swapping zusammenhängt ? `
Jain. Es heißt erstmal nur das -in dem Screenshot Fall aus Sicht des os der hm-rpc Prozess vom iobroker der Verursacher von hohem Speicherverbrauch war. Erstmal nur ein Indiz.
Steht hm-rpc bei allen Fundstellen?
-
Nein es sind verschiedene Fehlerursachen.
sshd
rpi2
radar
hm-rpc
kthreadd
siehe Datei (Ich hab mal ein paar Einträge zusammengefasst)
-
Dann musst du auf Häufungen schauen. Das os erwischt nichts immer den hauptverursacher … falls es den in deinem Fall überhaupt gibt.
-
hm-rpc 1x
sshd 8x
radar 1x
kthreadd 2x
cron 4x
rpi2 1x
-
Kann jemand sagen was sshd für ein Prozess ist ? Zugriff über SSH ?


{kind=link}
{kind=link}