InfluxDB - alte Werte automatisch löschen
-
@wolfgangfb lies mal hier da hatte ich das Thema auch auf dem Schirm.
-
@homoran sagte in InfluxDB - alte Werte automatisch löschen:
@wolfgangfb sagte in InfluxDB - alte Werte automatisch löschen:
Kann man das irgendwie automatisch hinbekommen dass einzelne Werte nur 24 Stunden gehalten werden?
sollte in den Objekten einstellbar sein
Das hatte ich gehofft, finde aber nichts wo ich das konfigurieren könnte.
-
@wolfgangfb sagte in InfluxDB - alte Werte automatisch löschen:
finde aber nichts wo ich das konfigurieren könnte.
dann zeig mal!
ich hab nur history, da gibt es das -
@homoran sagte in InfluxDB - alte Werte automatisch löschen:
@wolfgangfb sagte in InfluxDB - alte Werte automatisch löschen:
finde aber nichts wo ich das konfigurieren könnte.
dann zeig mal!
ich hab nur history, da gibt es dasSo sieht das aus:
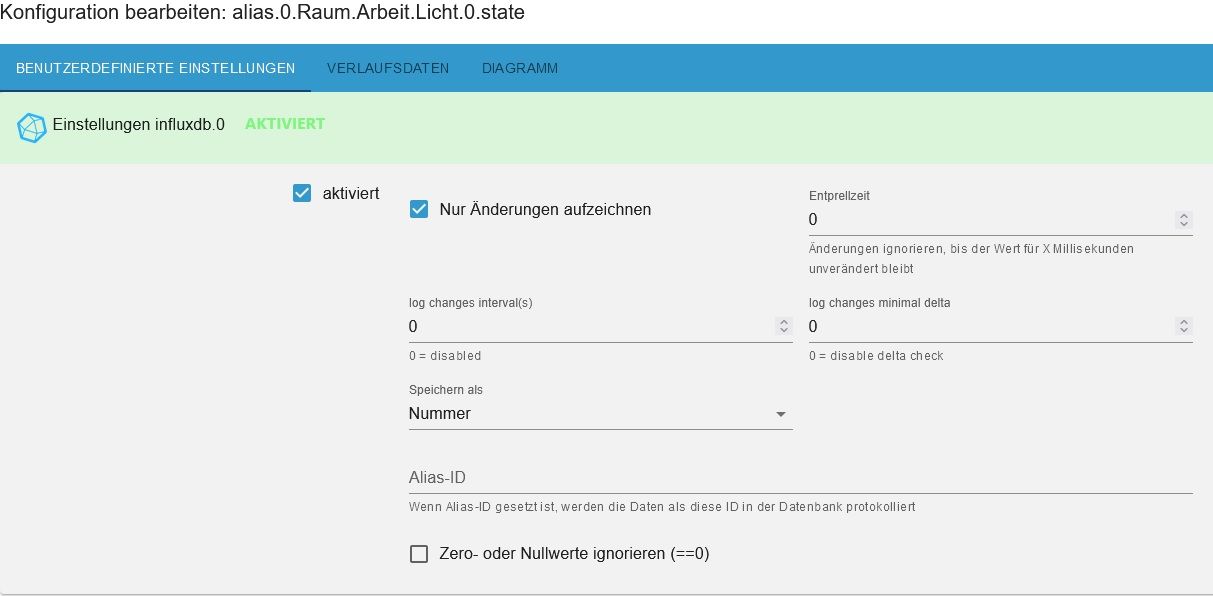
-
@wolfgangfb
Das letzte Bild ist noch aus der 2.x von Influx, jetzt habe ich auf 3.2.0 aktualisiert, es gibt zwar jetzt mehr Einstellungen, aer das automatisches Löschen ist immer noch nicht da.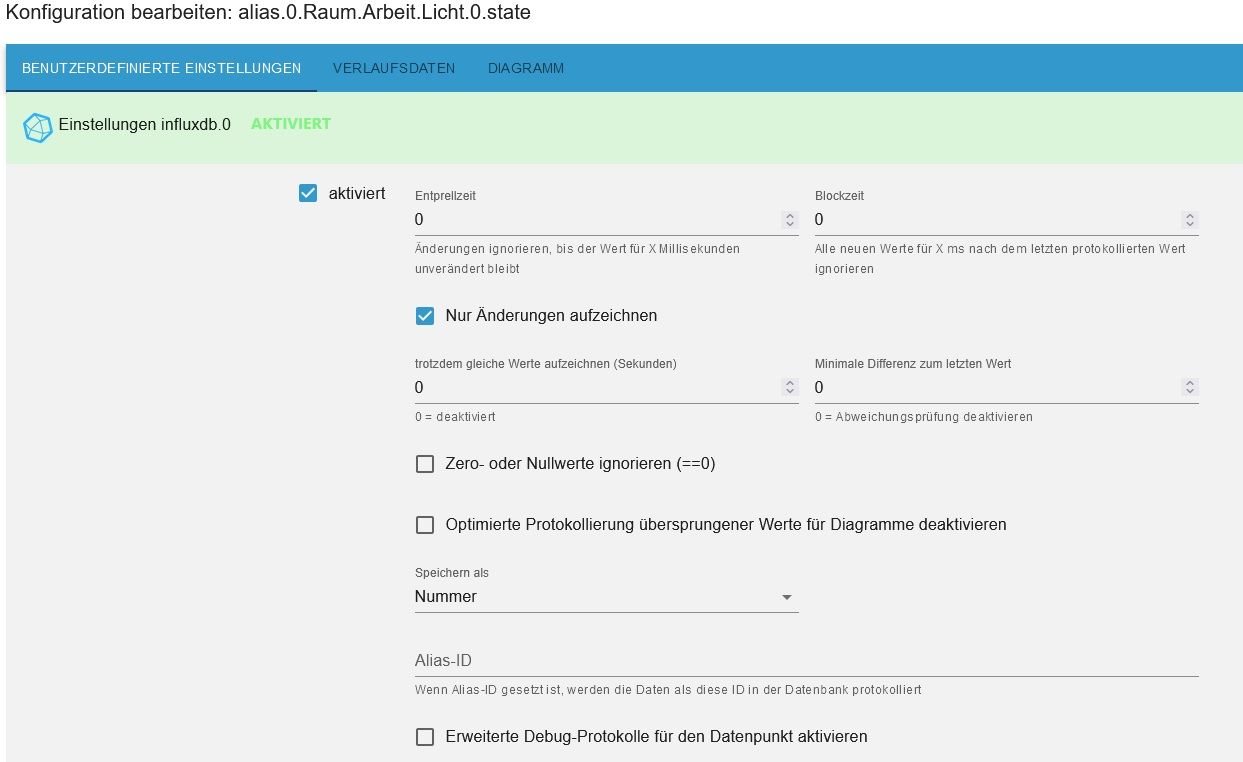
-
Du legst ein zusätzliches Bucket an mit einer anderen Retention Time.
Dann eine zustätzlich Instanz deines influx DB Adapters. In den Objekten kannst Du dann auswählen in welches Bucket geschrieben wird, in dem Du die entsprechende Instanz auswählst.
Eigentlich super easy
Man kann natürlich auch alles programmieren. Aber influx ist eigentlich eine zeitbasierende Datenbank die gerade zeitliche Infos entsprechend selbst veraltet. Für Konsilidierungstasks, solltest Du in Influx selbst anlegen. Da gibts im Tutorial Beispiele, wie man Sekunden- oder Minutenwerte in Tageswerte konsolidiert etc.
Dies Konsolidierungstasks werden als Downsampling Tasks bezeichnet:
https://docs.influxdata.com/influxdb/v2.4/process-data/common-tasks/downsample-data/
Auch hier werden die Daten dann von einem Bucket (Datenbank) in die nächste geschrieben, die unterschiedliche Retention Times haben. Das sind aber Aufgaben für die InfluxDB und keine Tasks des iobrokers.
Wie gesagt für einfache Lösungen, kannst du mehrere Instanzen nehmen. Also einen Monat und unendlich. Für weitere Konsolidierungen solltest Du Dich näher mit InfluxDB beschäftigen.
-
Ist das dann die "Storage Vorhaltezeit"?
Bei der Lösung mit mehreren Instanzen muss ich aber von vorne herein wissen, ob ich ein Objekt unendlich lange behalten will oder nur eine gewisse Zeit, richtig?
Kann ich dann in Grafana auch Daten aus beiden Instanzen gleichzeitig anzeigen lassen?Gruß Wolfgang
-
@wolfgangfb sagte in InfluxDB - alte Werte automatisch löschen:
aer das automatisches Löschen ist immer noch nicht da.
dann bleib ich doch lieber bei history
-
@wolfgangfb Die Vorhaltezeit stellt nur retention Time im Bucket der Influx DB ein. Sprich das gilt für die gesamte Db. Ja und das mit den Objekten musst Du im Vorfeld wissen.
Wie gesagt die Downsizing Tasks solltest Du innerhalb der InfluxDB definieren.
In Grafana kenn ich mich weniger aus, aber ich denke in den Datenquellen musst Du ja auch immer die Datenquellen angeben. Sprich da steht ja von welchem bucket die Daten geholt werden.
from(bucket: "iobroker") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "mqtt.1.shellies.shellyplug-s-999.relay.0.power")Wenn Du über Abfragen Daten aus der DB löschen willst: s. hier: https://docs.influxdata.com/influxdb/v2.4/write-data/delete-data/
über predicate nur bestimmte Werte, sonst kann man auch die ganze Datenbank von Daten befreien.
Man kann auch Eine Range dynamisch bestimmen:
from(bucket: "iobroker") |> range("start": 0,"stop": -1mo)Wenn man so was macht kommen alle Daten älter als 1 Monat und die kannst dann löschen.
-
@homoran Das ist auch im SQL Adapter so, dass man es dort per DP festlegt. Die InfluxDB geht aber davon aus, dass man diese ganzen Zeitberechnungen und Konsolidierungen etc. innerhalb der Influx DB macht, weil sie dafür ja gebaut ist.
-
@mickym sagte in InfluxDB - alte Werte automatisch löschen:
innerhalb der Influx DB macht, weil sie dafür ja gebaut ist.
dann sollte aber der Adapter bestenfalls diese Konfiguration bereitstellen.
-
@homoran Wie gesagt - der Adapter stellt das ja um. Gibt einige Beiträge, die sich wundern warum sie ein bucket in der InfluxDB auf unendlich gestellt haben und dann im Adapter auf einen Monat und sich dann wundern, wenn sie wieder in die Influx DB schauen, warum da wieder auf 1 Monat umgestellt ist.
-
@mickym sagte in InfluxDB - alte Werte automatisch löschen:
der Adapter stellt das ja um.
aber doch nur global wenn ich das richtig verstanden habe.
will man unterschiedliche Aufbewahrungszeiten haben muss man "tricksen" und wie dann?
braucht es für jede unterschiedliche Rückhaltezeit eine Instanz? -
@homoran Ja. Wie gesagt Konsolidieren oder Daten löschen - sollte man dann in der influxDB. Wenn der Adapter solche Aufgaben über nehmen sollte, dann müsste er solche Abfragen, die ich unten gepostet habe, zyklisch an die Influx Db schicken.
Also entweder man macht es grob über die Instanz. Ansonsten MUSS man es zwingend innerhalb der influxDB machen.
Man kann auch selbst solche Queries machen und dann über den Adapter schicken, aber so komfortabel wie mit dem History oder SQL Adapter geht es nicht, wo der Adapter das pro Datenpunkt ausführt. Es ging technisch schon, aber dazu müsste der Adapterentwickler des influxDB Adapters das entsprechend einbauen und diesen "Löschtask" genauso einmal pro Tag ausführen, wie beim History- oder SQL Adapter.
@homoran sagte in InfluxDB - alte Werte automatisch löschen:
will man unterschiedliche Aufbewahrungszeiten haben muss man "tricksen" und wie dann?
Wie gesagt tasks in der Influx DB erstellen.
Ob man die gleiche relative Schreibweise verwenden kann weiß ich nicht. Dazu stecke ich nicht tief genug drin.
-
@mickym sagte in InfluxDB - alte Werte automatisch löschen:
Wie gesagt tasks in der Influx DB erstellen.
dann habe ich es entweder nicht verstanden oder nicht richtig rübergebracht.
Men Verständnis war, dass ich für verschiedene Rückhaltezeiten auch verschiedene buckets (was immer das sein mag) erstelken muss.
Mein Gedanke für eine "relativ" einfache Anwendung wären dann mehrere Instanzen des influxDB-Adapters, bei dem jede Instanz auf ein bucket zugreift
-
@homoran Ja ist ja richtig - wenn Du keine Tasks in der influx DB definieren willst und keine Abfragen aus dem iobroker machen willst, kannst Du das nur über verschiedene Instanzen die auf verschiedene Datenbanken mit unterschiedlicher Retention Time zugreifen.
