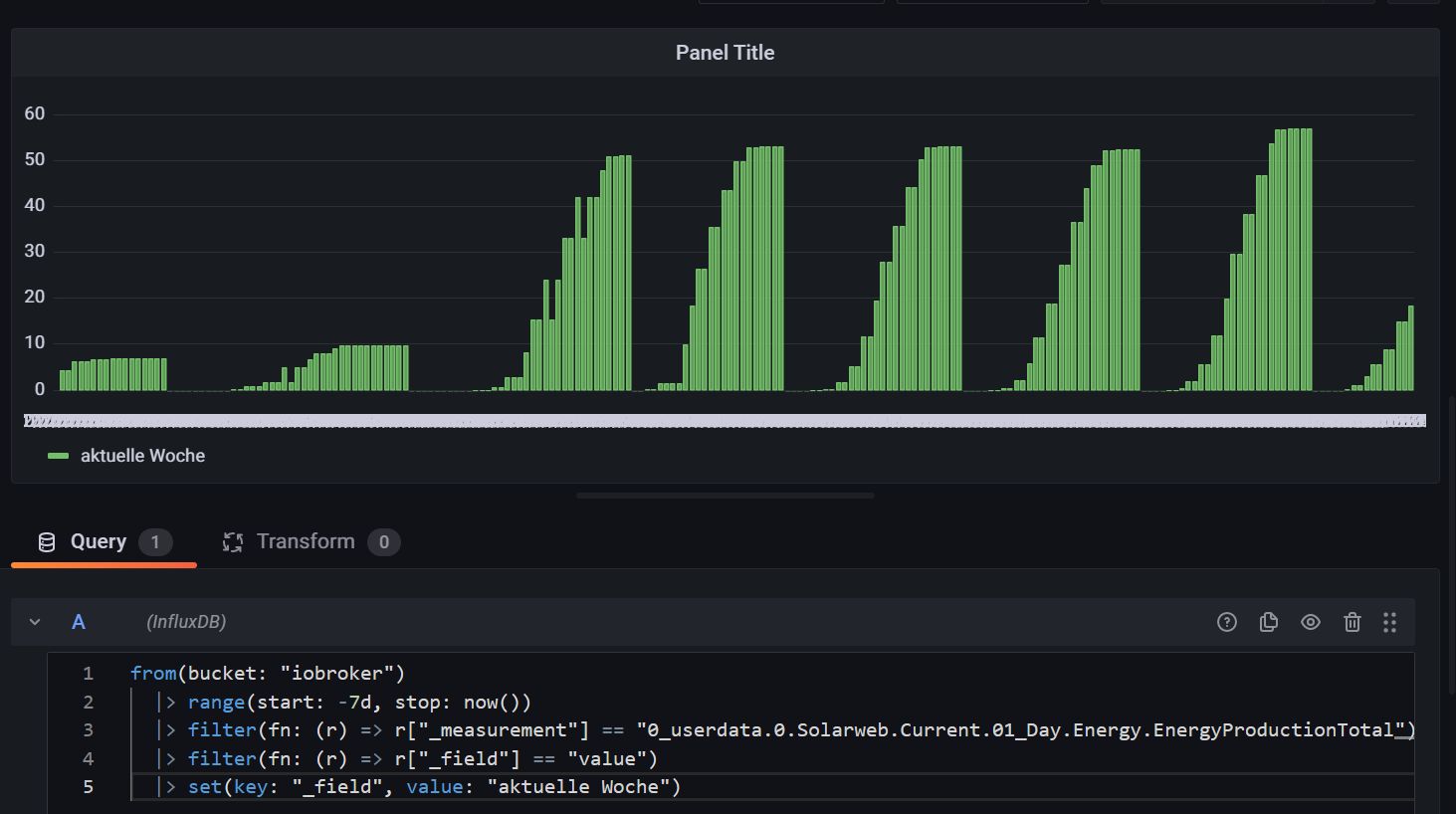
Vergleichskurve in Grafana mit influx Daten
-
@dp20eic
mit der Timezone selbst hab ich keine Probleme, somit kann ich es im Code einfach weg lassen.Jedoch bekomme ich ja trotzdem nur den aktuellen Tag angezeigt.
-
Moin,
ach so, ich dachte, es geht Dir um die Errors.
Ich kenne die Datenbasis, auf die Du Dich beziehst, nicht.
Wenn ich heute mal etwas Zeit habe, schaue ich mir die Abfrage, an. Sie sieht mir aber erst einmal oK aus.VG
Bernd -
@maximal1981 sagte in Vergleichskurve in Grafana mit influx Daten:
Jedoch bekomme ich ja trotzdem nur den aktuellen Tag angezeigt.
Moin,
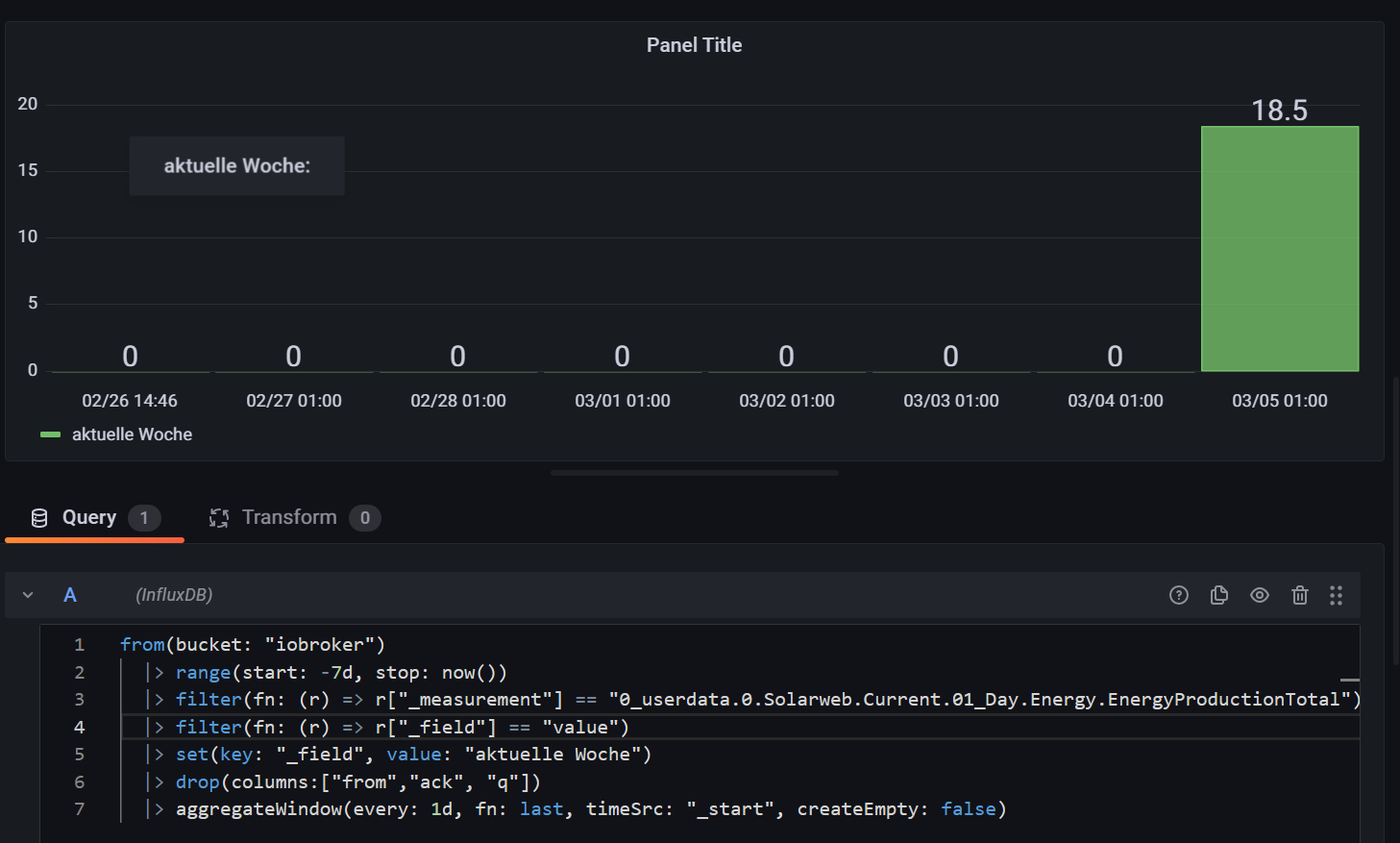
ich habe das mal auf ähnliche Daten angewendet, Stromverbrauch total. Ich habe nur wegen UTC Zeit, die Zone-Info wieder reingenommen.
Bei mr funktionieren die Abfragen wie gewollt.
Da scheint was mit den Daten nicht zu passen, kannst Du mal für zwei/drei Wochen einen CSV Export machen und zur Verfügung stellen, damit ich die mal in ein Test-Bucket schreibe und dann mit Deinen Daten gegenprüfen kann?
VG
Bernd -
@dp20eic
30 Tage zum spielen^^ -
Moin,
also nach dem Import der Daten in mein
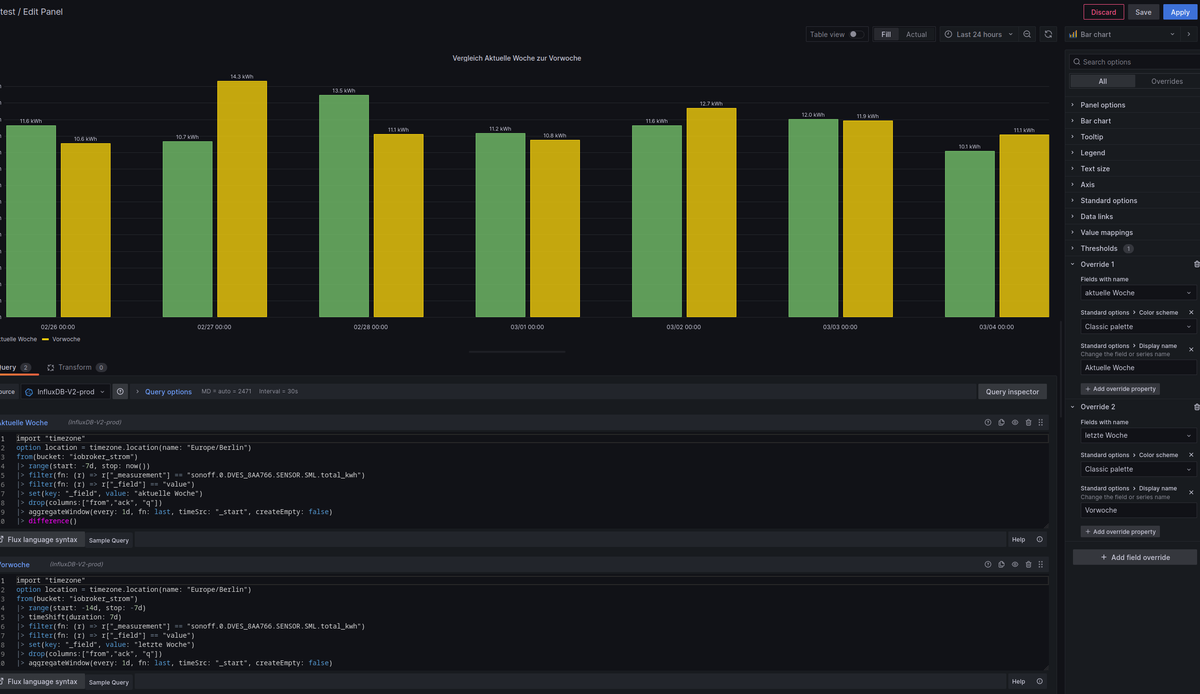
test_bucketund Einbinden inGrafanasehen die Abfragen bei mir wie folgt aus:Aktuelle Woche, mit
difference(nonNegative: true ...
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "aktuelle Woche") //|> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: true, columns: ["_value"])Aktuelle Woche, mit
difference(nonNegative: false ...
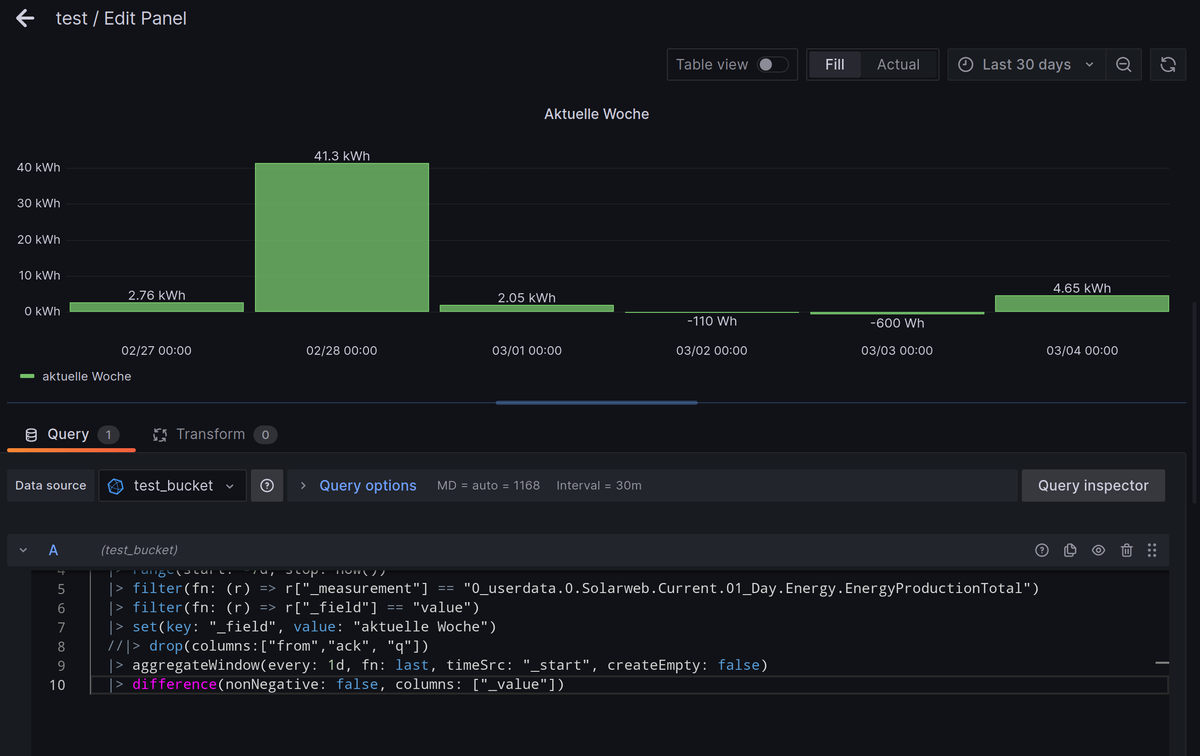
import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "aktuelle Woche") //|> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"])Aktuelle und vergangene Woche zusammen:
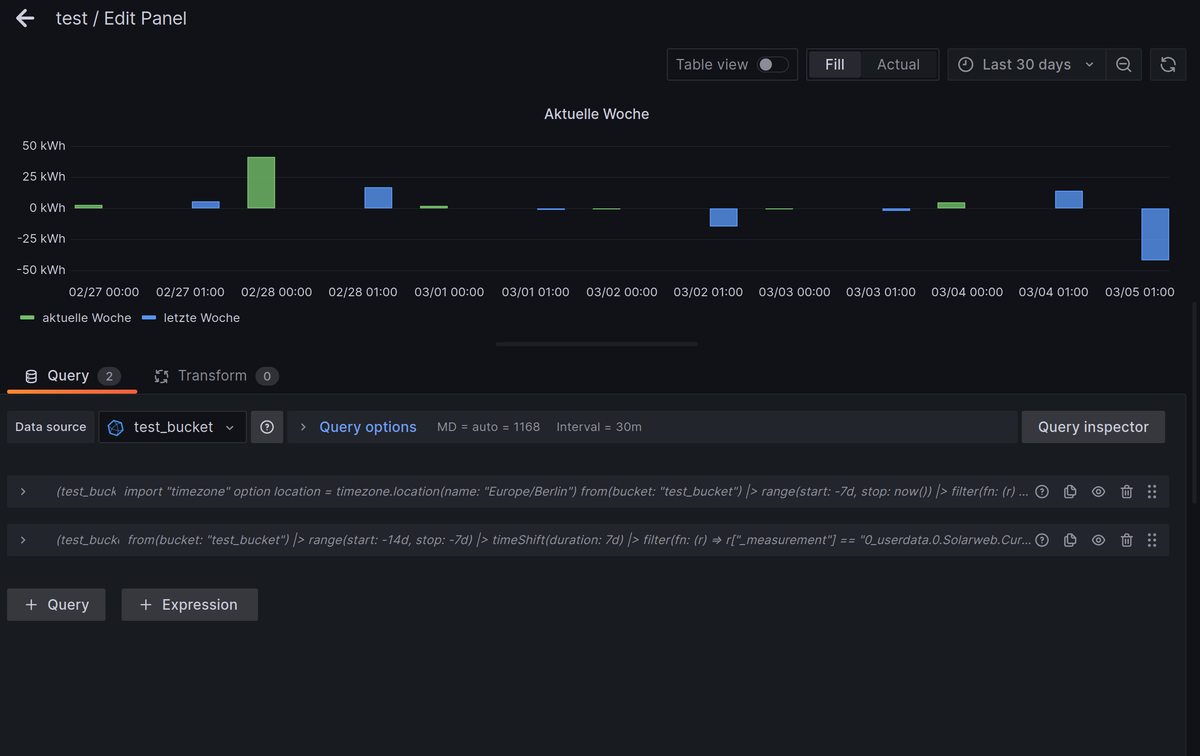
Query A: import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "aktuelle Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"]) Query B: import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -14d, stop: -7d) |> timeShift(duration: 7d) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "letzte Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"])Also so wie ich das sehe, funktionieren die Abfragen.
VG
Bernd -
@dp20eic
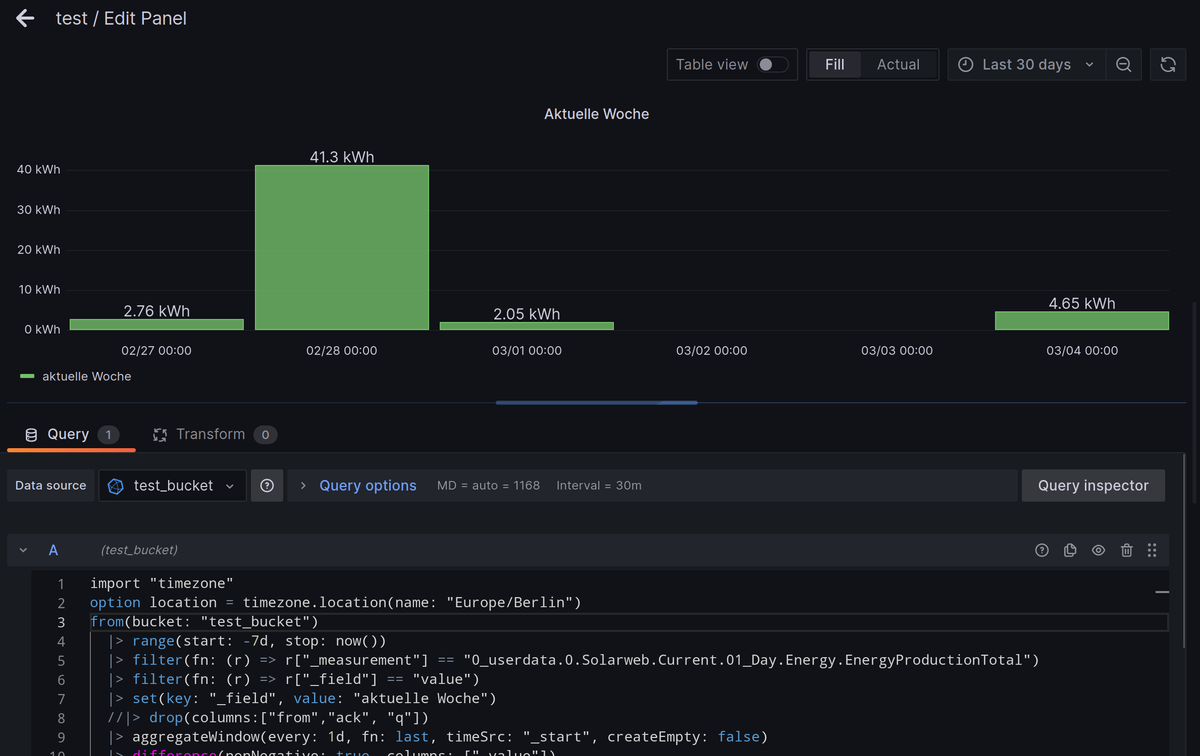
danke für die Mühe. Aber irgendwas stimmt nicht. so sehen die Daten in influx aus:
negative Erzeugung gibt es ja nicht und die Werte stimmen auch nicht

keine Ahnung was hier falsch läuft.und die Meldung bekomme ich unter Teil B bzw. links oben in der Diagramm-Ecke:
Post "http://...:8086/api/v2/query?org=my-org": context deadline exceeded (Client.Timeout exceeded while awaiting headers) -
@maximal1981 sagte in Vergleichskurve in Grafana mit influx Daten:
negative Erzeugung gibt es ja nicht u
Moin,
doch, nach meinem Verständnis, bekommst Du negativ Werte, da Du ja zum Vortag berechnest, sagen wir mal Du hast 10, dann am nachfolgenden 12, dann ist das +2, wenn Du dann aber am dritten Tag 8 hast, dann ist das -4.Bei meinem Beispiel mit dem Stromverbrauch, der ist annähernd linear, somit immer nur +.
Deine Werte sehen bei mir auch so aus:

-
@dp20eic
ok, so wollte ich das gar nicht
bin das vermutlich falsch angegangen.Ich wollte eine Darstellung jeden Tages mit der Gesamterzeugung ohne Differenz im vergleich zur Vorwoche (damit ich optisch die Differenz sehe)

Nur mal die aktuelle Woche und das macht aggregiert keinen Sinn, oder?
-
Moin,
wie ermittelst Du?
SourceAnalytix Adapter?
Skript?Wenn, dann brauchst Du erst einmal einen echten totalen Wert, der nur größer werden kann. Dann kannst Du auch mit der ursprünglichen Abfrage arbeiten.
Ich habe mal bei Deinen Tageswerten, in die Abfrage ein
cumulativeSumhinzugefügt.import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "aktuelle Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) //|> difference(nonNegative: false, columns: ["_value"])Dann sieht das für die Woche so aus:
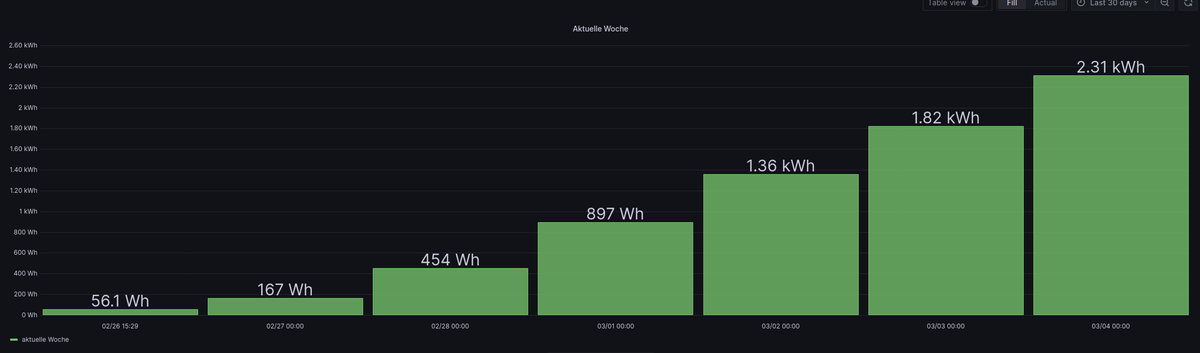
Wenn ich dann die Vorwoche noch dazu hole, dann passt natürlich die X-Achse nicht mehr
Query A: import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "aktuelle Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) //|> difference(nonNegative: false, columns: ["_value"]) Query B: import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -14d, stop: -7d) |> timeShift(duration: 7d) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "letzte Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) //|> difference(nonNegative: false, columns: ["_value"])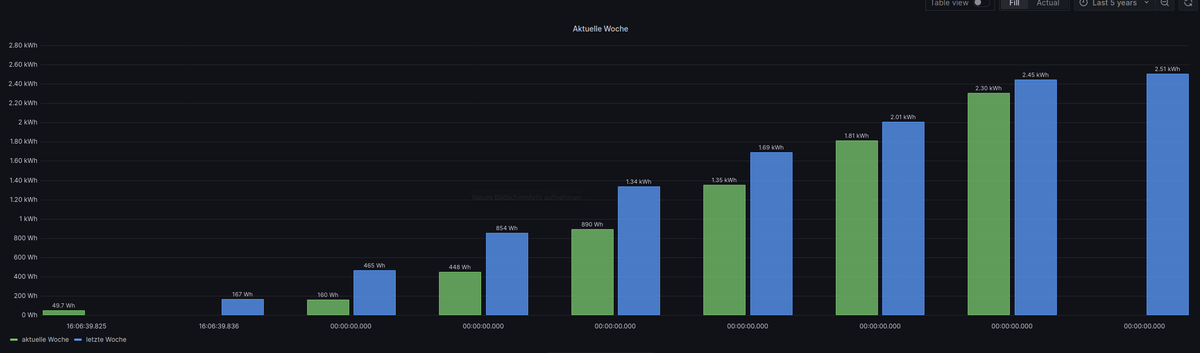
Ich schaue gerade wie ich die Zeitwerte aus Deinen Daten in Wochentag Namen ummodeln kann, dann würde man auf der X-Achse nur noch der Wochenname stehen
VG
Bernd -
@dp20eic
achso, der wird täglich auf 0 gesetzt.
also muss ich mir nur einen anderen Datenpunkt holen, das war mir nicht bewusst. -
@dp20eic
jetzt geht zumindest A. B mag mich jedoch trotzdem nicht.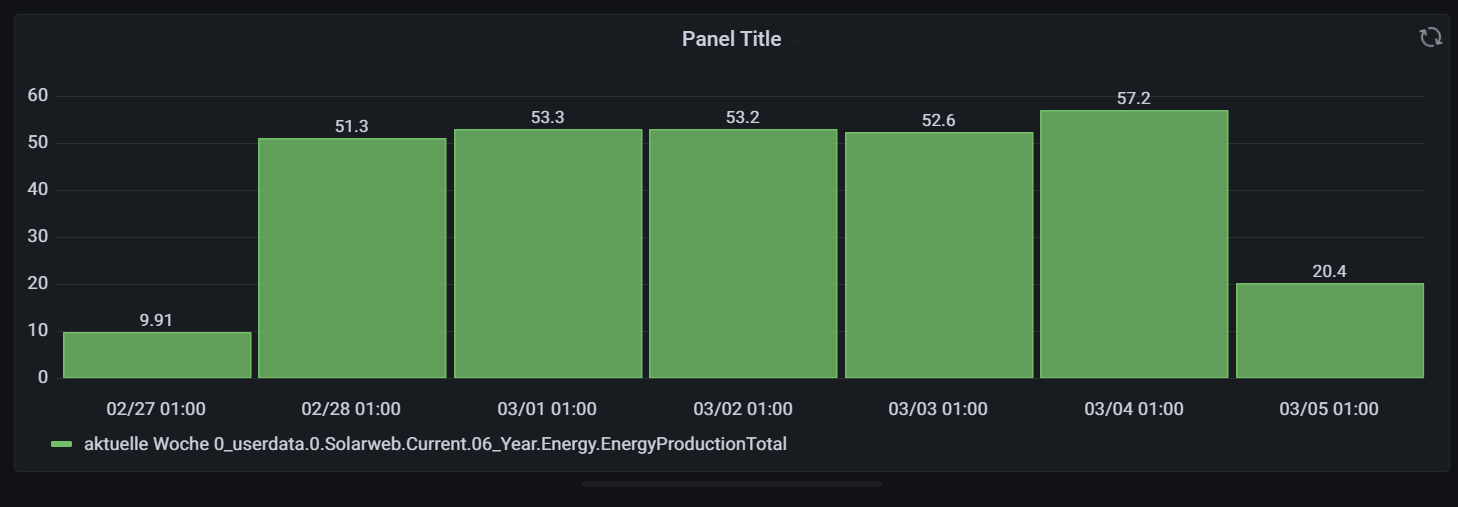
eine neue csv falls benötigt
-
Moin,
wenn Du jetzt aus einem Jahreswert aufbaust, dann ja, kannst mir da noch mal einen Abzug manchen.
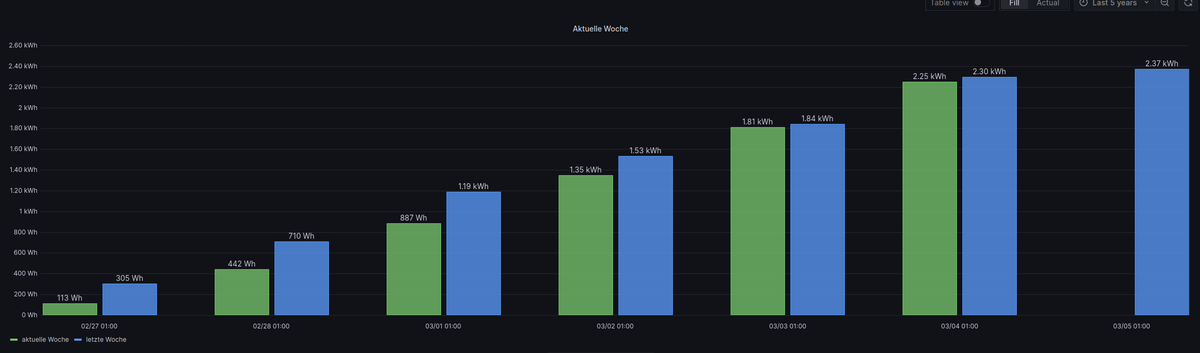
Query A: import "experimental/date/boundaries" thisWeek = boundaries.week() //lastWeek = boundaries.week(week_offset: -1) from(bucket: "test_bucket") |> range(start: thisWeek.start, stop: thisWeek.stop) //|> range(start: lastWeek.start, stop: lastWeek.stop) //|> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "aktuelle Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) //|> difference(nonNegative: false, columns: ["_value"]) Query B: import "experimental/date/boundaries" //thisWeek = boundaries.week() lastWeek = boundaries.week(week_offset: -1) from(bucket: "test_bucket") //|> range(start: thisWeek.start, stop: thisWeek.stop) |> range(start: lastWeek.start, stop: lastWeek.stop) //|> range(start: -14d, stop: -7d) |> timeShift(duration: 7d) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.01_Day.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "letzte Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) //|> difference(nonNegative: false, columns: ["_value"])VG
BerndEdit
Hab die Datei gesehen, hat sich etwas versteckt")
-
@dp20eic
wenn ich das richtig gelesen habe, sind die Wochentage Settings in den Grundeinstellungen, somit muss man damit leben -
Moin,
Mit den Jahreswerten:
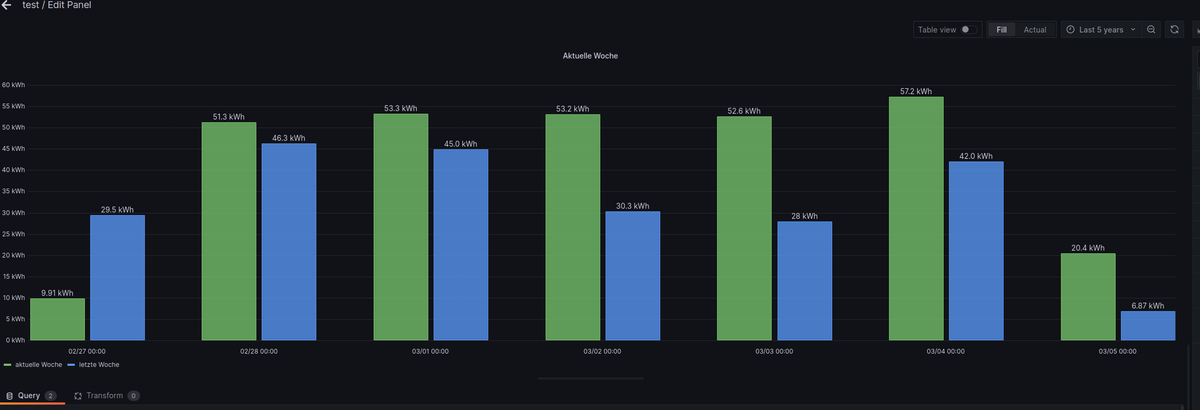
Query A = aktuelle Woche import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.06_Year.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "aktuelle Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"]) Query B = letzte Woche import "timezone" option location = timezone.location(name: "Europe/Berlin") from(bucket: "test_bucket") |> range(start: -14d, stop: -7d) |> timeShift(duration: 7d) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.06_Year.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") |> set(key: "_field", value: "letzte Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"])So wenn ich auf die Woche schaue, also von Montag - Sonntag
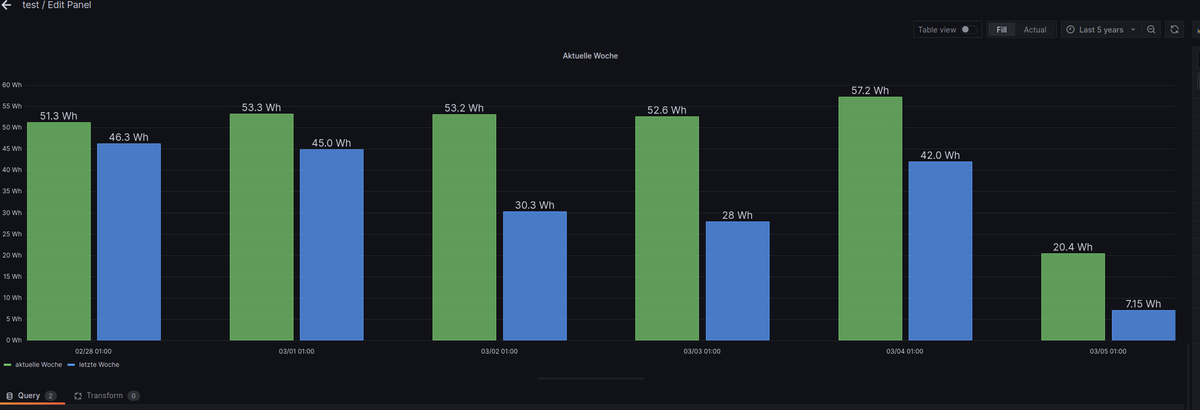
Query A import "experimental/date/boundaries" thisWeek = boundaries.week() //lastWeek = boundaries.week(week_offset: -1) from(bucket: "test_bucket") |> range(start: thisWeek.start, stop: thisWeek.stop) //|> range(start: lastWeek.start, stop: lastWeek.stop) //|> range(start: -7d, stop: now()) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.06_Year.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") //|> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "aktuelle Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"]) Query B import "experimental/date/boundaries" //thisWeek = boundaries.week() lastWeek = boundaries.week(week_offset: -1) from(bucket: "test_bucket") //|> range(start: thisWeek.start, stop: thisWeek.stop) |> range(start: lastWeek.start, stop: lastWeek.stop) //|> range(start: -14d, stop: -7d) |> timeShift(duration: 7d) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Solarweb.Current.06_Year.Energy.EnergyProductionTotal") |> filter(fn: (r) => r["_field"] == "value") //|> cumulativeSum(columns: ["_value"]) |> set(key: "_field", value: "letzte Woche") |> drop(columns:["from","ack", "q"]) |> aggregateWindow(every: 1d, fn: last, timeSrc: "_start", createEmpty: false) |> difference(nonNegative: false, columns: ["_value"])Das mit der X-Achse bekomme ich auch noch hin, muss nur ab und an andere Dinge machen und bin dann von Mittwoch im Urlaub, etwas Sonne tanken
VG
Bernd -
@dp20eic
dann flott Koffer richten, bei dem was ich dich bereits gequält habe, hast du dir das redlich verdientich glaube bei mir liegt irgendwas anderes quer.
Jedes Mal beim Teil B mit dem Versatz um 7 Tage rödelt der Aktualisierungskreis eine gefüllte Ewigkeit und dann wieder die tolle Meldung:Post "http://xyz:8086/api/v2/query?org=my-org": net/http: timeout awaiting response headers (Client.Timeout exceeded while awaiting headers)
-
@maximal1981 sagte in Vergleichskurve in Grafana mit influx Daten:
Post "http://xyz:8086/api/v2/query?org=my-org": net/http: timeout awaiting response headers (Client.Timeout exceeded while awaiting headers)
Moin,
habe den Überblick verloren, wie bist Du unterwegs?
Getrennte Docker, LXC Container, VMs?
Lass mal ein
pingnebenher laufen vom Grafana zurinfluxDbund Stress das System mal.Du siehst dann, wenn Du den
pingstoppst--- influxdb-v2-prod.fritz.box ping statistics --- 26 packets transmitted, 26 received, 0% packet loss, time 25035ms rtt min/avg/max/mdev = 0.038/0.059/0.078/0.009 msUnd schau mal ob Du
packeteverlierst.VG
Bernd -
@dp20eic
ich hab mal ein grafana update gemacht.War ein großer Fehler, da meine dashboards nicht mehr angezeigt wurden, da die settings auf default gesetzt werden.
Ist aber leicht zu fixen wenn man eine Ahnung hat warum (hatte ich aber nicht^^), deswegen hier gleich mal die nötigen Schritte:
- die grafana setting Datei ausfindig machen
- und folgende Werte darin anpassen:
[auth.anonymous] # enable anonymous access enabled = true # specify organization name that should be used for unauthenticated users org_name = Main Org. <-- egal welche Org ihr habt nicht ändern # specify role for unauthenticated users org_role = Viewer # mask the Grafana version number for unauthenticated users # Geschmacksache entscheidet selbst hide_version = true#################################### Security ############################ [security] /* ein wenig runter, ist für iobroker notwendig; direkt geht es aber natürlich nicht eingebettet sagt auch der Schalter set to true if you want to allow browsers to render Grafana in a <frame>, <iframe>, <embed> or <object>. default is false. */ allow_embedding = truejetzt aber zurück zum Grundproblem.
läuft aktuell alles auf einem Lenovo X1 mit einem i5 und Win 10 ohne Virtualisierung also alles direkt installiert.
Habe mich via rdp drauf geschmissen und das panel neu berechnen lassen und musste mir selbst das tolle Bild reinziehen
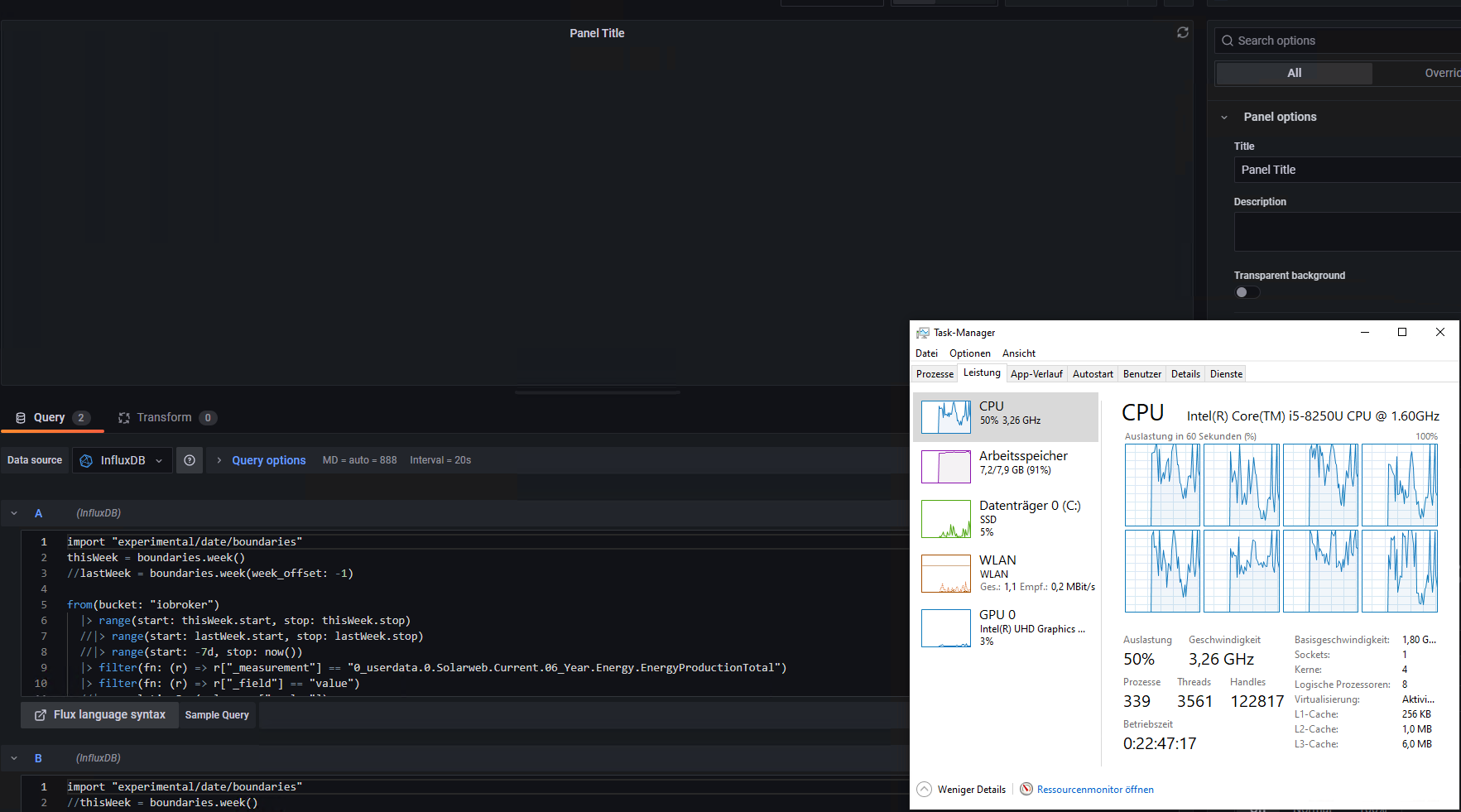
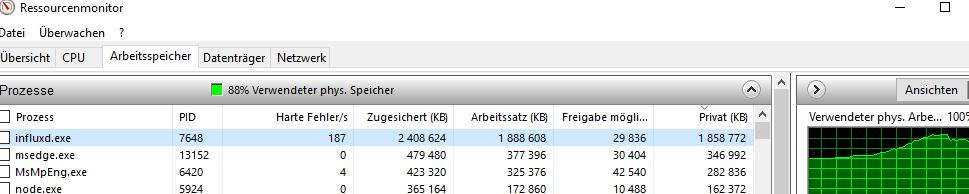
influx war kurzfristig über 2 GB RAM und geht dann idle wieder auf ca. 250 MB zurück. Jedich bekomme ich dort keinen Fehler angezeigt, aber auch nicht den Teil B.
Nächste Möglichkeit wäre influx Update, hoffe nur das geht besser von der Hand und ich zerschieße mir nichts.
-
Moin,
Backup, ist besser zu haben, als zu brauchen
Leider bin ich bei Windows raus, ist definitiv nicht meine Baustelle.
VG
Bernd -
@dp20eic
backup hatte ich, nur die ini hatte ich übersehen.ich hoffe, dass es ein Win 10 Problem ist, bin wegen Leistungsproblemen von einem Raspi 4 auf Win 10 umgestiegen. Warte noch auf einen günstigen und vernünftigen NUC um mit Proxmox zu starten, sofern mir keiner was besseres erzählt.
vor der DB Update hab ich aber ein wenig Respekt. würdest du das aktuelle Verhalten echt auf Windows schieben?
Recht viel bleibt nicht mehr über außer DB Version -
Moin,
kann ich wirklich nicht einschätzen, dazu kenne ich mich mit Win zu wenig aus.Die Abfragen kann man ja abschalten
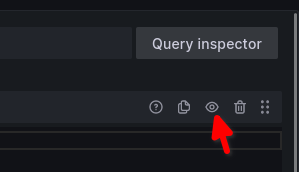
Knips mal A aus und nur B und dann mal andersherum.
VG
Bernd