Frage : Migrate MySQL nach Influxdb
-
@ullij Erstmal vielen Dank..
Ich musste das Skript leicht anpassen auf sqlite, hab jetzt aber einen Fehler, der mit der Anpassung selbst eigentlich nichts zu tun hat:
### MySQL DB info ### #import MySQLdb #conn = MySQLdb.connect(host="localhost", # your host, usually localhost # user="john", # your username # passwd="megajonhy", # your password # db="jonhydb") # name of the data base ### PostgreSQL DB info ### #import psycopg2 #import psycopg2.extras import sqlite3 ##### # connection data for PostgreSQL #conn = psycopg2.connect("dbname=xxx user=xxx password=xxx host=xxx.xxx.xxx.xxx port =5432") ##### conn = sqlite3.connect('/opt/iobroker/iobroker-data/sqlite/sqlite.db') # InfluxDB info # from influxdb import InfluxDBClient # #####connection data for InfluxDB##### influxClient = InfluxDBClient(host='localhost', port=8086, username='xxxx', password='xxxx!', database='xxxx') ##### #influxClient.delete_database(influx_db_name) #influxClient.create_database(influx_db_name) # dictates how columns will be mapped to key/fields in InfluxDB schema = { "time_column": "time", # the column that will be used as the time stamp in influx "columns_to_fields" : ["ack","q", "from","value"], # columns that will map to fields # "columns_to_tags" : ["",...], # columns that will map to tags "table_name_to_measurement" : "name", # table name that will be mapped to measurement } ''' Generates an collection of influxdb points from the given SQL records ''' def generate_influx_points(records): influx_points = [] for record in records: #tags = {}, fields = {} #for tag_label in schema['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in schema['columns_to_fields']: if field_label == "ack": record[field_label] = bool(record[field_label]) fields[field_label] = record[field_label] influx_points.append({ "measurement": record[schema['table_name_to_measurement']], #"tags": tags, "time": record[schema['time_column']], "fields": fields }) return influx_points # query relational DB for all records curr = conn.cursor() # curr = conn.cursor(dictionary=True) ##### # SQL query for PostgreSQL, syntax for MySQL differs # query provide desired columns as a view on the sql server # request data from SQL, adjust ...from <view name> curr.execute("Select * from xxx;") ##### row_count = 0 # process 1000 records at a time while True: print("Processing row #" + str(row_count + 1)) selected_rows = curr.fetchmany(1000) influxClient.write_points(generate_influx_points(selected_rows)) row_count += 1000 if len(selected_rows) < 1000: break conn.close()Fehler:
user@UbuntuHomeAutomation2:~$ python3 sql2influx3.py Processing row #1 Traceback (most recent call last): File "sql2influx3.py", line 75, in <module> influxClient.write_points(generate_influx_points(selected_rows)) File "sql2influx3.py", line 50, in generate_influx_points record[field_label] = bool(record[field_label]) TypeError: tuple indices must be integers or slices, not str user@UbuntuHomeAutomation2:~$Vielleicht hat ja jemand ne Lösung.
-
@thomas-herrmann
wünsche ein frohes neues Jahr.Du meintest sicherlich @JackGruber.
Ich kann Dir bei dem Skript (leider) nicht helfen.
Gruß -
@ullij
Wünsch dir ebenso ein frohes Neues.
Es bezieht sich auf das Skript in deinem Post vom 14. Apr. 2020, 20:42: [https://forum.iobroker.net/topic/12482/frage-migrate-mysql-nach-influxdb/26](Link Adresse)Aber vielleicht hat ja noch jemand eine Idee, woran es liegen kann.
-
@thomas-herrmann
Hallo Thomas,
ich versuche es doch mal, allerdings habe ich die Umgebung dafür nicht mehr aktiv...testen ist also nicht ohne weiteres. Und Sqlite habe ich noch nie nicht verwendet.Das Python skript habe ich 1:1 aus der genanntenten Quelle übernommen und nur den Input bereitgestellt,
Du hast in dem Teil des Skriptes wo die Daten geschrieben werden sollen den Feldtyp geändert (Zeile 50). Die Fehlermeldung deutet darauf hin das Du einen String übergibst, aber ein Integer erwartet wird.
Versuch doch mal das Skript im Original laufen zu lassen und die Inputdaten passend zur Verfügung zu stellen.
Gruß
Ulli -
@ullij Danke, aber das habe ich vorher natürlich schon versucht.
Die Änderung stammt von @JackGruber [https://forum.iobroker.net/topic/12482/frage-migrate-mysql-nach-influxdb/36] -
Hallo zusammen,
vielen Dank für das Script und da drumherum hier @JackGruber @UlliJ - ich bin gerade dabei, ca 60mio Datensätze von einer SQL auf eine influx zu migrieren.
Ich stoße hierbei leider immer wieder mitten in der Übertragung auf folgenden Fehler:Total metrics in ts_number: 1 0_userdata.0.Variablen.Strom.Steckdose_Dachgeschoss(ID: 9, type: float) (1/1) Processing row 1 to 1,000 from LIMIT 0 / 100,000 ts_number - 0_userdata.0.Variablen.Strom.Steckdose_Dachgeschoss (1/1) InfluxDB error float() argument must be a string or a real number, not 'NoneType'Kann ich das entweder irgendwie überspringen oder gar besser konvertieren in eine 0 oder etwas in der Art?
Vielen Dank
Gruß
Christoph
-
Falscher Thread, sorry. Bitte löschen.
-
Hatte gerade genau das gleiche Problem. Scheinbar sind da teilweise "nicht" float Werte in mysql DB vorhanden.
z.b. nullHabe es recht simple gelöst, indem einfach alle Werte die nicht Float sind auf 0 gesetzt werden.
Änderung im Script war einfach beim float konvertieren ein "or 0" anfügen:# Daten in richtigen Typ wandeln if field_label == "value": if datatype == 0: # ts_number fields["value"] = float(record["value"] or 0) elif datatype == 1: # ts_string fields["value"] = str(record["value"]) elif datatype == 2: # ts_bool fields["value"] = bool(record["value"])@JackGruber
Vielen Dank für das coole Script. Einfach genial! -
@umbm influx v2 kann auch noch influx v1 api auth influx v1 auth create
-
Ich muss 3 Jahre Daten importieren, aber irgendwann bekomme ich folgende Fehlermeldung:
InfluxDB error HTTPConnectionPool(host='192.168.178.155', port=8086): Max retries exceeded with url: /write?db=iobroker&rp=autogen (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fb8267db6d0>: Failed to establish a new connection: [Errno 111] Connection refused'))Die Batchsize habe ich hoch und runter getestet. Der Fehler ist sehr sporadisch, aber kommt defintiv, entweder am Datensatz X oder Y.
Hat jemand noch eine Idee. Könnte mir vorstellen, dass es nur eine Server-Einstellung ist, aber ich finde die Stelle nicht. In Google findet man auch kaum etwas. Danke
Gruß
-
Jetzt muss ich auch noch mal was Banales nachfragen:
Bei den Datenpunkten ist ja im Moment die Aufzeichnung bei SQL aktiviert.
Ich nehme an ich muss erst die Aufzeichnung bei InfluxDB aktivieren damit es die Datenpunkte dort gibt und dann die Daten migrieren?Oder?
-
@bananajoe sagte in Frage : Migrate MySQL nach Influxdb:
Jetzt muss ich auch noch mal was Banales nachfragen:
Bei den Datenpunkten ist ja im Moment die Aufzeichnung bei SQL aktiviert.
Ich nehme an ich muss erst die Aufzeichnung bei InfluxDB aktivieren damit es die Datenpunkte dort gibt und dann die Daten migrieren?Oder?
Moin,
ich bin mir mal wieder nicht sicher, ob ich alles korrekt verstehe, aber hilft Dir evtl. diese Lösung weiter?
Query SQL-DB und SQL Funktion damit solltest Du dir eigentlich das Bucket und layout in InfluxDb automatisch anlegen.
Alles nicht getestet, da ich gerade keine Postgresql oder mariadb zur Hand habe.
VG
Bernd -
Ich meinte das:
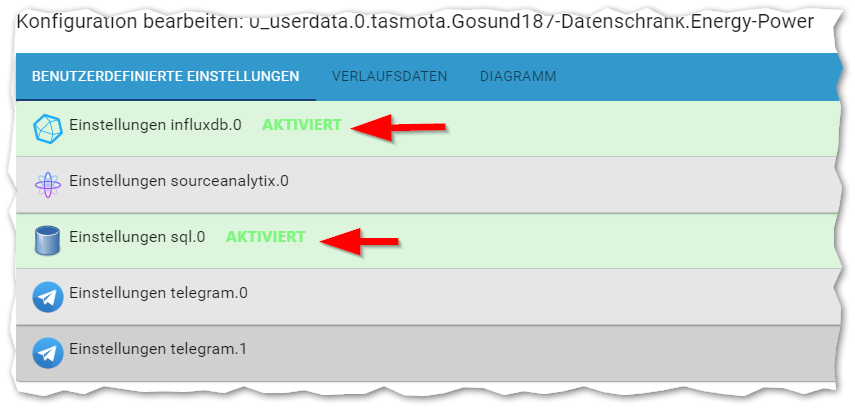
-
-
Hallo Zusammen,
erst mal vielen Dank an @JackGruber für das Script, es hat mir viel Arbeit erspart.
Da ich eine Microsoft SQL Datenbank haben, musste ich das Script etwas umschreiben (sorry @JackGruber ).Falls jemand diese Änderung benötigt, hier ist sie:
-
Ihr benötigt Python, ich habe diese Version installiert
https://www.python.org/downloads/release/python-3125/ -
Die Jason Datei wie folgt ergänzen. Ich habe Sie als migrateMSQL.py umbenannt:
Bitte MSQL Login Daten entsprechend anpassen <xxxxx> und auch für die Influx Datenbank die Zugangsdaten anpassen. Hier ist es wichtig das Token zu verwenden das man
bei INfluxDB V2 anlegen muss.
Bei mir ist InfluxDB ein extra Container im Proxmox und daher musste ich hier auch noch die IP Adresse angeben.
{ "MSQL": { "server": "localhost", "user": "iobroker", "password": "xxxxxxxx", "database": "iobroker" }, "MySQL": { "host": "localhost", "port": 3306, "database": "iobroker", "user": "iobroker", "password": "iobroker" }, "InfluxDB": { "host": "192.168.2.xxx", "ssl": false, "port": 8086, "database": "iobroker", "retention_policy": "autogen", "user": "admin", "password": "7TBAUCsxxxxxY2Sde9QAiAYTDo0WzwerJ8BqfOvxxxx19a8jwYzociuB_4RFVGIDAkN7MA==", "store_ack_boolean": true } }- Bitte dann die PYMSSQL Bibliothek installieren, diese wird für den Zugriff auf MSQL benötigt.
Ich habe das in der Commandozeile unter einem Windows Betriebsystem gemacht, in dieser Reihenfolge:
pip install -r requirements.txt pip install pymssql-
Achtet darauf, dass Ihr im IOBroker die InfluxDB Schnittstelle zusätzlich zu euren SQL Interface installiert und ich musste leider für alle Datenpunkte die InfluxDB Protokollierung einzeln aktivieren und ein
stellen. Da die InfluxDB Schnittstelle keine individuelle Löschung pro Datenpunkte erlaubt, habe ich 2 InfluxDB Instanzen installiert mit unterschiedlichen Löschzeiten (eigentlich eine für unbegrenzt und eine für 1 Jahr).
Hier werde ich noch schauen was InfluxDB kann, soweit ich weiß sollte man das in Influx direkt programmieren und damit entsprechende Daten verdichten bzw. löschen. -
Und nun das Phyton Script ausführen, hier gibt es ein paar Anpassungen wegen MSQL z.B. "import pymssql", wie Ihr unten im geänderten SourceCode seht.
Ich habe bewusst darauf verzichtet meine Änderungen "schön zu machen", da ich es nur einmalig brauche, aber wichtig für mich war, es funktioniert.
Die Ausführung kann sehr sehr lange dauern, daher habt Geduld. Damit Ihr die Scriptausgaben auch seht, nicht einfach auf migrateMSQL.py klicken, sonst geht das Command Fenster sofort wieder zu.
Öffnet am Besten ein CMD, wechselt in der Verzeichnis wo Ihr requirements.txt und migrateMSQL.py abgelegt habt und gebt dann folgende Zeile ein.
python migrateMSQL.py ALLUnd hier nun der Inhalt von migrateMSQL.py:
import json import os import sys import time import pymssql try: from influxdb import InfluxDBClient import pymssql except Exception as ex: print(ex) print("Please install all requirements!") sys.exit(1) if not sys.version_info >= (3, 6): print("Python version to old!") print(sys.version) sys.exit(1) # Load DB Settings database_file = os.path.join(os.path.dirname( os.path.realpath(__file__)), "database.json") if not os.path.exists(database_file): print("Please rename database.json.example to database.json") sys.exit(1) f = open(database_file, 'r') db = f.read() f.close() try: db = json.loads(db) except json.decoder.JSONDecodeError as ex: print(database_file + "Json is not valid!") print(ex) sys.exit(1) except Exception as ex: print("Unhandeld Exception") print(ex) sys.exit(1) try: print("SQL CONNECT: server="+db['MSQL']['server']) MSSQL_CONNECTION = pymssql.connect(server=db['MSQL']['server'], user=db['MSQL']['user'], password=db['MSQL']['password'], database=db['MSQL']['database'], as_dict=True) # MYSQL_CONNECTION = pymysql.connect(host=db['MySQL']['host'], # port=db['MySQL']['port'], # user=db['MySQL']['user'], # password=db['MySQL']['password'], # db=db['MySQL']['database']) except pymssql.OperationalError as error: print(error) sys.exit(1) except Exception as ex: print("MSSQL connection error") print(ex) sys.exit(1) INFLUXDB_CONNECTION = InfluxDBClient(host=db['InfluxDB']['host'], ssl=db['InfluxDB']['ssl'], verify_ssl=True, port=db['InfluxDB']['port'], username=db['InfluxDB']['user'], password=db['InfluxDB']['password'], database=db['InfluxDB']['database']) # Select datapoints if len(sys.argv) > 1 and sys.argv[1].upper().strip() == "ALL": MIGRATE_DATAPOINT = "" print("Migrate ALL datapoints ...") elif len(sys.argv) == 2: MIGRATE_DATAPOINT = " AND name LIKE '" + sys.argv[1] + "' " print("Migrate '" + sys.argv[1] + "' datapoint(s) ...") else: print("To migrate all datapoints run '" + sys.argv[0] + " ALL'") print("To migrate one datapoints run '" + sys.argv[0] + " <DATAPONTNAME>'") print("To migrate a set of datapoints run '" + sys.argv[0] + ' "hm-rega.0.%"' + "'") sys.exit(1) print("") # dictates how columns will be mapped to key/fields in InfluxDB SCHEMA = { "time_column": "time", # the column that will be used as the time stamp in influx # columns that will map to fields "columns_to_fields": ["ack", "q", "from", "value"], # "columns_to_tags" : ["",...], # columns that will map to tags # table name that will be mapped to measurement "table_name_to_measurement": "name", } DATATYPES = ["float", "string", "boolean"] ##### # Generates an collection of influxdb points from the given SQL records ##### def generate_influx_points(datatype, records): influx_points = [] for record in records: #tags = {}, fields = {} # for tag_label in SCHEMA['columns_to_tags']: # tags[tag_label] = record[tag_label] for field_label in SCHEMA['columns_to_fields']: if db['InfluxDB']['store_ack_boolean'] == True: if field_label == "ack": if (record[field_label] == 1 or record[field_label] == "True" or record[field_label] == True): record[field_label] = True else: record[field_label] = False fields[field_label] = record[field_label] # Daten in richtigen Typ wandeln if field_label == "value": if datatype == 0: # ts_number fields["value"] = float(record["value"] or 0) elif datatype == 1: # ts_string fields["value"] = str(record["value"]) elif datatype == 2: # ts_bool fields["value"] = bool(record["value"]) influx_points.append({ "measurement": record[SCHEMA['table_name_to_measurement']], # "tags": tags, "time": record[SCHEMA['time_column']], "fields": fields }) return influx_points def query_metrics(table): MSSQL_CURSOR.execute( "SELECT name, id, type FROM datapoints WHERE id IN(SELECT DISTINCT id FROM " + table + ")" + MIGRATE_DATAPOINT) rows = MSSQL_CURSOR.fetchall() print('Total metrics in ' + table + ": " + str(MSSQL_CURSOR.rowcount)) return rows def migrate_datapoints(table): query_max_rows = 100000 # prevent run out of mermory limit on SQL DB process_max_rows = 1000 migrated_datapoints = 0 metrics = query_metrics(table) metric_nr = 0 metric_count = str(len(metrics)) processed_rows = 0 for metric in metrics: metric_nr += 1 print(metric['name'] + "(ID: " + str(metric['id']) + ", type: " + DATATYPES[metric['type']] + ")" + " (" + str(metric_nr) + "/" + str(metric_count) + ")") start_row = 0 processed_rows = 0 while True: query = """SELECT d.name, m.ack AS ack, CAST(m.q AS FLOAT) AS q, s.name AS [from], m.val AS value, CAST(m.ts * 1000000 AS BIGINT) AS time FROM [dbo].[""" + table + """] AS m LEFT JOIN [dbo].[datapoints] AS d ON m.id = d.id LEFT JOIN [dbo].[sources] AS s ON m._from = s.id WHERE m.q = 0 AND d.id = """ + str(metric['id']) + """ ORDER BY m.ts DESC OFFSET """ + str(start_row) + """ ROWS FETCH NEXT """ + str(query_max_rows) + """ ROWS ONLY; """ #### alte query für MySQL # query = """SELECT d.name, # m.ack AS 'ack', # (m.q*1.0) AS 'q', # s.name AS "from", # m.val AS 'value', # (m.ts*1000000) AS'time' # FROM """ + table + """ AS m # LEFT JOIN datapoints AS d ON m.id=d.id # LEFT JOIN sources AS s ON m._from=s.id # WHERE q=0 AND d.id = """ + str(metric['id']) + """ # ORDER BY m.ts desc # LIMIT """ + str(start_row) + """, """ + str(query_max_rows) # MSSQL_CURSOR.execute(query) if MSSQL_CURSOR.rowcount == 0: break # process x records at a time while True: selected_rows = MSSQL_CURSOR.fetchmany(process_max_rows) if len(selected_rows) == 0: break print(f"Processing row {processed_rows + 1:,} to {processed_rows + len(selected_rows):,} from LIMIT {start_row:,} / {start_row + query_max_rows:,} " + table + " - " + metric['name'] + " (" + str(metric_nr) + "/" + str(metric_count) + ")") migrated_datapoints += len(selected_rows) try: INFLUXDB_CONNECTION.write_points(generate_influx_points(metric['type'], selected_rows), retention_policy=db['InfluxDB']['retention_policy']) except Exception as ex: print("InfluxDB error") print(ex) sys.exit(1) processed_rows += len(selected_rows) start_row += query_max_rows print("") return migrated_datapoints #MSSQL_CURSOR = MSSQL_CONNECTION.cursor(cursor=pymssql.cursors.DictCursor) MSSQL_CURSOR = MSSQL_CONNECTION.cursor() migrated = 0 migrated += migrate_datapoints("ts_number") migrated += migrate_datapoints("ts_bool") migrated += migrate_datapoints("ts_string") print(f"Migrated: {migrated:,}") MSSQL_CONNECTION.close()- Ausgeführt
Final habe ich damit 45,770,061 Datensätzen auf einmal migrieren können und stichprobenartig mal über die Weboberfläche von INfluxDB geprüft ob soweit alles passt, noch ist mir kein Fehler aufgefallen.
Ich hoffe diese Anleitung hilft denen weiter die statt mySQL ein MSSQL verwenden.
Danke nochmals an @JackGruber für die tolle Arbeit.
Gruss
Thomas -
-
Ich versuche das Script von @JackGruber zu benutzen um meine Daten aus der Homeassistant MariaDB nach Influx zu transferieren. Bekomme aber leider folgenden Fehler:
(.venv) pi@raspberrypi:~/migrate2influxdb_JackGruber $ python migrate.py ALL (1698, "Access denied for user 'homeassistant'@'localhost'") (.venv) pi@raspberrypi:~/migrate2influxdb_JackGruber $Der User homeassistant hat aber meiner Meinung nach die richtigen Rechte:
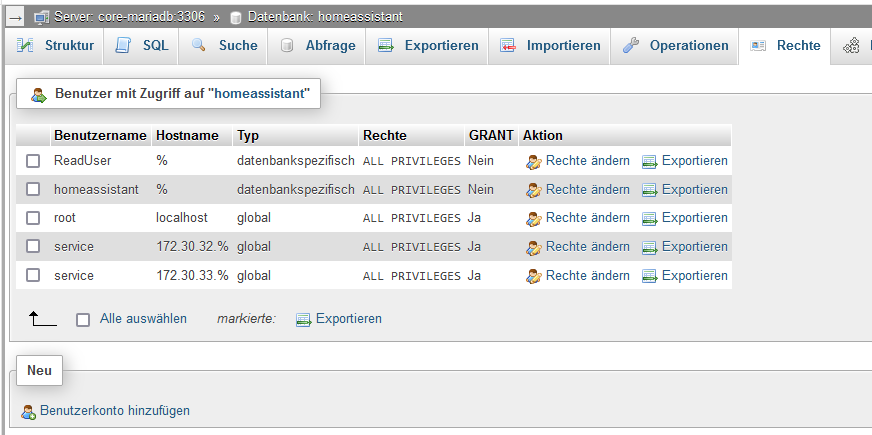
Anbei auch die Konfiguration von database.json:
{ "MySQL": { "host": "localhost", "port": 3306, "database": "homeassistant", "user": "homeassistant", "password": "XXXXXX" }, "InfluxDB": { "host": "localhost", "ssl": false, "port": 8086, "database": "Test_temp", "retention_policy": "autogen", "user": "Micha", "password": "XXXXXX", "store_ack_boolean": true } }Hat jemand eine Idee und kann mir helfen? Vielen Dank schonmal ....
-
@micha70 pffft % könnte sein das das für alle Hosts steht ...
was passiert denn wenn du
mysql -uhomeassistent -pdeinpasswort homeassistenteingibst? kannst du dich verbinden oder nicht? Wenn nicht passen die rechte eben nicht.
Benutzertyp "datenbankspezifisch" macht mich nachdenklich.
Was hats du denn im SQL-Adapater von ioBroker eingetragen als Benutzer?
