Bestimmte Daten aus einer Webseite auslesen und steuern
-
Hallo
Ich möchte von einer Webseite (Behncke Poolsteuerungen) einige Daten wie z.B. die Wassertemperatur auslesen und in einer zweiten Phase auch Steuerkommandos senden z.B. Umwälzpumpe ein-, ausschalten.Wenn ich im Browser (Firefox) im eingeloggten Zustand den Seitenquellentext anzeigen lasse kann ich alle Werte finden, Total 8999 Zeilen.
Ausschnitt vom Browser:
// PARAMETER
// =========
// VALUE
var oValue = 0;
oValue = getRealValue('277', '0.1', '1');
vMenuItems['12231'] += ShowElementParameterTypValue( AREA_MAINLIST,
'261678',
'Wassertemperatur',
'°C',
IsElementVisible(261678),
oEditMode ? 'cell_main_attributes CellTypeElement' : 'cell_main_attributes CellTypeElementNoneEditMode',
oValue);Kann mir jemand helfen wie ich das Vorhaben mit Node Red oder ioBroker realisieren kann. Im Internet finde ich einige Hinweise aber wie ich konkret, sinnvoll vorgehe ist mir nicht klar.
Zum Testen machte ich in Node Red einen kleine Flow mit http request (GET) mit den notwendigen Login Informationen (Benutzername, Kennwort) und erhoffte den Inhalt der Webseite im Debuggfeld zu sehen.
Es erscheinen jedoch nur wenige Zeichen (ca. 970) obwohl zu Beginn steht msg.payload: string[9088], was muss ich machen um den gesamten String zu sehen, im Browser-Debugg sehe ich 8999 Zeilen unter index.php.
Wenn in der Spalte Debugger schon nicht der Inhalt der gesamten Webseite erscheint wird es wahrscheinlich auch nicht möglich sein bestimmte Werte herauszulesen oder ist meine Überlegung falsch?Wie gehe ich am Besten vor um z.B. die aktuelle Wassertemperatur auszulesen?
Ich hoffe sehr jemand kann mir beim Auslesen, Filtern weiterhelfen.Vielen Dank im Voraus und freundliche Grüsse
Heinz -
Ohne Dir jetzt im Detail zu helfen, weil ich nun kein HTML Spezialist bin übergibst Du die payload aus dem http-request node an einen http (node) unter parser.
Dort kann man dann angeben, welche Teile er aus einer Webseite extrahieren soll. Ich habs aber selber noch nicht gemacht, aber mit dem parse http node sollte es gehen.Hier habe ich noch ein Video gefunden - das es im Prinzip erklärt_
Webseite parsen -
@mickym Danke für den Hinweis.
Ich versuchte die Projektierung sinngemäss, entsprechend dem Video, funktioniert jedoch bei meiner Applikation nicht. Ich denke das erste Problem bei der Abfrage besteht darin, dass gar nicht die ganze Webseite eingelesen wird. In der Debugg-Spalte sehe ich immer nur die ersten ca. 970 Zeichen.Das steht in der Debugg-Spalte:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="de" lang="de"><head> <title>Remoteportal Behncke</title> <base href="https://behncke.remoteportal.de/" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <link rel="stylesheet" type="text/css" href="static/css/jquery-ui_1-11-4.css?rev=11134" /> <link rel="stylesheet" type="text/css" href="static/css/jquery-ui_1-11-4.structure.css?rev=11134" /> <link rel="stylesheet" type="text/css" href="static/css/jquery-ui_1-11-4.theme.css?rev=11134" /> <link rel="stylesheet" type="text/css" href="static/css/all_old.css?rev=11134" /> <link href="https://fonts.googleapis.com/icon?family=Material+Icons" rel="stylesheet"> <link rel="stylesheet" type="text/css" href="static/css/layout-startseite.css?rev=11134" /> <link rel="stylesheet" type="text/css" href="static/css/theme/BEHNCKE/desi...Irgendetwas mache ich anscheinend grundlegend falsch oder kann es sein, dass via Node ‚http request‘ mit der Methode ‚GET‘ eventuell die Webseite gar nicht ausgelesen werden kann oder wird in der Debugg-Spalte einfach nicht die gesamte Webseite (Quelltext) angezeigt?
Was muss im Node ‚html‘ unter ‚Selektor‘ eingetragen werden, die Daten sind ja mit javascript aufbereitet?
-
Nun wie gesagt - ich bin nun auch nicht der Superfachmann, was Webseiten betrifft. Falls die Website zum Beispiel xml zurückgibt, dann hast Du ja auch andere Parser zur Verfügung.
Als erstes musst Du halt mal über den Quelltext des Debuggers des Browser prüfen, ob da Deine Werte im Klartext zu lesen sind.
Die sind in jedem Fall mit einem Tag umschlossen - der auch wieder endet.
Dass die Debug-Spalte nur die ersten 970 Zeichen anzeigt, kann einfach der Darstellung geschuldet sein und muss nicht zwangsläufig heißen, dass nicht alle Daten eingelesen wurden.In dem Selektor muss der Tag stehen.
Aus Deinem geposteten Quell- Text ```
<title>Remoteportal Behncke</title>müsstestet Du dann als Selektor "title" eingeben und dann sollten alle Titel in einem Array in msg.payload aus dem HTML node rauskommen.
Poste doch mal den Teil des Quelltext aus Deinem Browser, wo die Werte im Klartext drinstehen.
-
Der Quellcode postete ich im ersten Beitrag unter 'Ausschnitt vom Browser:'
Die Wassertemperatur ist dort als '277' = 27.7°C zu sehen. Die ganze Sequenz ist innerhalb des Javascripts <script>, </script>. Ein Versuch mit dem Selektor 'script' ergibt in der Debugg-Spalte array(7), die arrays 0..4 sind leer, in den arrays 5 und 6 erscheinen Daten jedoch kann ich die Sequenz mit der Wassertemperatur nicht sehen, aber wahrscheinlich ist es so wie Du vermutest, dass in der Debugg-Spalte nicht alles gezeigt wird.Nach dem ‚http node‘ projektierte ich den ‚function node‘ mit folgender Function:
if (context.count){
context.count = 0;
}
for (var i = 0; i < 7; i++){
if(msg.payload[i].includes('Wassertemperatur')){
context.count++;
}
}
msg.payload = context.count;
return msg;in der Debugg-Spalte steht ‚msg.payload : undefined‘
Die Herausforderung ist die Wasseristtemperatur, als variable Zahl, herauszufiltern, leider gibt es keine eindeutige Kennung nach welcher gesucht werden könnte, auch das Wort ‚Wassertemperatur‘ kommt im Quelltext 6 mal vor und die Zahl ‚277‘ (Isttemperatur) gibt es 3 mal und ändert sich effektiv je nach Wasseristtemperatur. Ich weiss nicht ob man auf die Zeilennummer (4268) gemäss Quelltext triggern könnte und diese in einen String speichern, vorausgesetzt die Wassertemperatur ist immer in der gleichen Zeile. Mit String-Manipulationen könnte man dann die Isttemperatur separieren.
Ist mein Vorhaben überhaupt realisierbar?
-
Ich kann Dir das nicht mit Sicherheit beantworten, ob es realisierbar ist.
Evtl. mal mit einem Selektor über den Script - z. Bsp "body" nutzen.
Wenn es in der msg drin ist dann kann das sicher irgendwie mit RegEx herausfiltern.
Ich denke da müsste aber jemand helfen, der sich mit dem Webseitenaufbau besser auskennt.
Am Besten wäre natürlich wenn es so eine Art API gäbe, wo Du über HTTP die Daten direkt aufbereitet bekämst. -
Ich habe versuchshalber den Inhalt welcher das Node ‚http request‘ liest in ein File geschrieben und auch dort drin ist nur ein ganz kleiner Teil der gesamten http-Seite. Ich bin ziemlich unsicher ob wirklich die gesamte http-Seite gelesen wird. Könnte es sein, dass bei einer Abfrage durch eine Maschine (Node Red) bewusst nicht alle Daten der Webseite gelesen werden können.
Betreffend Zugriff via API warte ich noch auf Antwort vom Lieferanten.Vielleicht meldet sich noch jemand der die Problematik kennt.
-
@bugs
es gibt 2 arten von quelltexte.
Einmal das was der Server an den Browser ausliefert.
und dann der den dir der Browser anzeigt, nachdem evtl. javascripts
weitere Daten abgerufen hat, die DOM (documend Object Model) weiter verändert hat.
Das was der Browser unbearbeitet erhält kannst du über die
Developer Tools im Browser dir anzeigen lassen (F12 und dann Reiter Network), zumindest bei Firefox und Chrome -
@OliverIO Danke für die Erklärung.
Wenn ich unter Firefox (F12) schaue finde ich kein Menüpunkt Network, unter Debugger-index.php sind alle Daten inkl. z.B. der Wassertemperatur ersichtlich. Bild Link)
Bild Link)Beim Chrome gibt es den Menüpunkt Network (Filter=all) und dann in einer Tabelle verschiedene Elemente.
Wo genau muss ich schauen?
-
@bugs das ist schon das verarbeitete, du musst bei ff unter netzwerkanalyse schauen, da sind die einzelnen requests mit dem jeweiligen response
bei chrome ist das sehr ähnlich -
@OliverIO
Mit Firefox unter Netzwerkanalyse in der Datei ajax.php (POST) und in der Spalte Antwort unter JSON-values[105] ist die Wassertemperatur mit der paramterid: 261678 und dem value: 277 sichtbar.
Sagt das jetzt, dass die Daten direkt vom Server gesendet werden oder erst nach Ausführung eines Javascripts?Inzwischen erhielt ich eine Dokumentation einer REST-API zur Kommunikation mit dem Remoteportal.
Hier einen Ausschnitt der Beschreibung:
REST-API zur Kommunikation mit dem Remoteportal
Die API ist erreichbar unter folgender URL:
api.<FIRMENNAME>.remoteportal.de/...
Die Authentifizierung erfolgt über HTTP-Basic-Auth, d.h. im HTTP-Header muss immer eine Benutzername-/Passwort-Kombination mitgesendet werden.
Weiterhin sollte im HTTP_ACCEPT das Datenformat angegeben werden. Momentan wird nur JSON unterstützt, d.h. im Header sollte „application/json“ angegeben werden. Wird „application/xml“ angegeben wird der Fehlercode „501-Not Implemented“ zurückgegeben. Standardmäßig wird JSON zurückgegeben.
Die mit der Funktion /languages ermittelten Sprachen können im Headerfeld HTTP_ACCEPT_LANGUAGE mit dem Code der Sprache explizit angefordert werden. Werden mehrere Sprachen angegeben, sollte der Quality-Faktor gesetzt werden. Wird das Feld nicht gesetzt, wird die Standardsprache zurückgegeben.
Im Headerfeld IF_NONE_MATCH sollte der ETag der letzten Anfrage mitgesendet werden. So kann entschieden werden, ob Daten gesendet werden müssen, oder ob der Statuscode 304 – Not Modified gesendet wird. Kann eine Benutzer-/Passwort-Kombination nicht verifiziert werden, wird der HTTP-Statuscode 401 – Unauthorized zurückgeliefert. WICHTIG: wenn man sich mit den Controllerdaten authentifizieren will, ist der Benutzername die MAC-Adresse des Controllers. Diese muss ohne die Doppelpunkte übetragen werden. Idealerweise sollte aber in der Anwendung die Eingabe mit Doppelpunkten ermöglicht werden, um das Verhalten mit der Oberfläche des Remoteportals konsistent zu halten.
Wird eine Funktion aufgerufen, die nicht existiert wird der HTTP-Statuscode 404 – Not Found zurückgeliefert.
Alle Datums-/Uhrzeitangaben werden als UNIX-Timestamp übermittelt.Versionen:
Die Versionierung erfolgt über den http-Header. Im Feld HTTP_ACCEPT muss eine Liste der zu verwendende API-Versionen angegeben werden. Sollen mehrere Versionen berücksichtigt werden, muss eine Liste übergeben werden, z.B. „api/v2 api/v3“.Funktionen:
/languages
Liefert eine Liste mit den verfügbaren Sprachen
Akzeptierte Methoden:
• GET
Rückgabe (Liste):
• id: Die ID der Sprache
• title Name der Sprache
• code Der Sprachcode
http-Statuscode:
• 200 OK
• 304 Not Modified/users
Liefert Informationen zum User zurück.
Akzeptierte Methoden:
• GET
Rückgabe:
• login Der verwendete Login-Name
• type Typ des Benutzers (customer, trader)
• user_id Die ID des Users
• firstname Vorname
• lastname Nachname
• company Firma
• time_zone_offset Zeitabweichung der Userzeit von UTC in Minuten
http-Statuscode:
• 200 OK
• 304 Not Modified
• 409 Der Loginname ist kein User, sondern ein ControllerLeider fehlen mir auch hier die Kenntnisse wie ich mit Node Red eine Abfrage erstellen kann.
Ich versuchte im Browser und auch in Node Red mit ‚http request Node‘ z.B. folgende Eingabe:api.behncke.remoteportal.de/users
Rückmeldung vom Browser: The requested URL was not found on this server.Debugging in Node Red:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>404 Not Found</title>
</head><body>
<h1>Not Found</h1>
<p>The requested URL was not found on this server.</p>
<hr>
<address>Apache/2.4.18 (Ubuntu) Server at api.behncke.remoteportal.de Port 80</address>
</body></html>Der HTTP-Statuscode 404-Not Found sagt, dass es die Funktion (/status) nicht gibt, gemäss API-Dokument ist das aber eine mögliche Funktion. Ich versuchte auch andere Funktionen, erhalte aber immer die Fehlermeldung ‚404‘.
-
@bugs mit node red kenne ich mich nicht im detail aus.
aber nach kurzer suche habe ich das gefunden
https://cookbook.nodered.org/http/parse-json-response
d.h. darüber kannst du die json daten erst einmal abrufen.
theoretisch müssten deine anderen parameter in dieser node ebenfalls konfigurierbar sein (login)
alternativ kannst du es mal mit basic authetication versuchen, so in die richtung:http://userid:password@api.behncke.remoteportal.de/hierderapipfad
ist eigentlich deprecated, aber viele server bieten das dennoch noch an
über weitere nodes kannst du dir dann die eigentlichen felder aus dem json ausgeben lassen
-
Das ist doch erst mal eine gute Nachricht und den JSON String in Node-Red zu parsen, dass ist ein Kinderspiel.
Im Moment scheint aber die Syntax der Befehle noch nicht bekannt zu sein.
Da Du jede API in der Regel auch über den Browser aufrufen kannst, so funktionierte das zumindest bei mir, würde ich grundsätzlich erst mal die Syntax im Browser ausprobieren, d.h. welchen HTTP String Du absetzen musst.
Die Rückgabe im Browser ist dann ein ganz normaler JSON String, den Du später in Node-Red ganz easy mit dem JSON Node parsen kannst, da dieser automatisch das Format erkennt und aus den JSON Objekten, Javascript Objekte macht.
Das hat also nichts mit Node-Red zu tun - sondern probiere die Abfrage erst im Browser und wenn diese funktioniert, dann kannst Du die in einem http-get node abfragen.
Wenn Du via Browser auf den Webserver zugreifst, wird im Normalfall bei ersten Mal sowieso das Authentifizierungsfenster aufpoppen - und die Usercredentials sind dann gecached für die Folgeaufrufe.Ich rufe zum Beispiel die API über einen Webserver so auf:
http://<http-server>/xml/jsonswitch.php?id={{{id}}}&set={{{set}}}Die Parameter ID und set gebe ich dann später als Input in meine HTTP-Request Node mit - aber Du musst halt vorher im Browser testen mit welchem Aufruf Du die JSON-Strings zurückbekommst - und das hat wie gesagt nichts mit Node-RED zu tun.
Hier auch noch ein Link, wie Du Header in Deinen HTTP-Request aus Node-RED mit senden kannst:
https://cookbook.nodered.org/http/set-request-headerDie sendest Du einfach über eine vorgeschaltete Funktionnode mit einem msg.header-Object mit.
Die Query - setzt Du wenn der Pfad gefunden wurde imm mit einem ? voran ab. Also wenn es status als validen Input gibt - die "http://url/pfad?status"
-
@mickym
Das geht nur wenn sich der Server Programmierer nicht so viel Mühe gemacht hat.
Browser über Adresszeile fragt immer über HTTP-Get ab. Wenn der Server allerdings ein HTTP-Post erwartet,
oder noch dazu den Header X-Requested-With: XMLHttpRequest abfragt und erwartet, dann hast du mit dem Browser Pech
und musst mit dem programmieren anfangen.Für solche Fälle nehme ich Postman
https://www.postman.com/
Sehr schönes Tool um solch Abfragen abzufangen bzw. zu testen. -
@OliverIO said in Bestimmte Daten aus einer Webseite auslesen und steuern:
@mickym
Das geht nur wenn sich der Server Programmierer nicht so viel Mühe gemacht hat.
Browser über Adresszeile fragt immer über HTTP-Get ab. Wenn der Server allerdings ein HTTP-Post erwartet,
oder noch dazu den Header X-Requested-With: XMLHttpRequest abfragt und erwartet, dann hast du mit dem Browser Pech
und musst mit dem programmieren anfangen.Für solche Fälle nehme ich Postman
https://www.postman.com/
Sehr schönes Tool um solch Abfragen abzufangen bzw. zu testen.Na das ist doch ein Supertipp - vielen Dank - werde ich mir auch anschauen - denn Du hast Recht verschiedene Header zu testen etc. kann man mit dem Browser nicht und für die Zukunft sicher wertvoll.
Trotzdem braucht @bugs wahrscheinlich Hilfe zur Syntax - und kann ich ihm natürlich auch nicht sagen.
Aber lange Rede kurzer Sinn, er muss halt erst mal wissen, wie er die API mit welchen Aufrufen nutzen kann und soll es erst dann in Node-Red umsetzen. Wie die Header zu setzen sind habe ich ja gepostet.
Grundsätzlich sollte man dann aber mit Node-Red die wichtigsten Dinge bei der Abfrage mitgeben können, siehe Node-Beschreibung:-
url
String
Wenn nicht im Node konfiguriert, setzt diese optionale Eigenschaft die URL der Anforderung. -
method
String
Wenn nicht im Node konfiguriert, setzt diese optionale Eigenschaft die HTTP-Methode der Anforderung. Muss einer von GET, PUT, POST, PATCH oder DELETE sein. -
headers
Objekt
Setzt die HTTP-Header der Anforderung. -
cookies
Objekt
Wenn gesetzt, kann es verwendet werden, um Cookies mit der Anforderung zu senden. -
payload
Wird als Hauptteil der Anforderung gesendet.
-
-
Zuerst vielen Dank für die aktive Unterstützung, das ist gar nicht selbstverständlich.
Es ist tatsächlich so, dass mir die Kenntnisse der Syntax mit HTTP und Node Red fehlen. Ich habe sehr vieles ausprobiert aber komme leider zu keinem Ergebnis.Kurz zu meiner Person, ich bin Ü65 und war in meinem aktiven Berufsleben im Bereich Steuerungen tätig. Viele Jahre programmierte ich SPSen und Prozessleitsysteme, vorwiegend mit Siemens-Produkte, für verfahrenstechnische Anlagen. Seit guten einem Jahr, begonnen mit FHEM, versuche ich hobbymässig unser EFH smarter zu machen. Dank Internet, Selbststudium und vor allem hilfreichen Fachleuten in verschiedenen Foren habe ich einiges umgesetzt. Im Einsatz sind zwei Raspberry Pi 3 und 4, einer im technischen Bereich als SPS, projektiert mit Codesys und einer als zentraler Server mit ioBroker und Node Red. Zur Kommunikation sind Ethernet, digitalSTROM, Enocean und Modbus-TCP im einsatz. Realisiert sind Storensteuerungen, Eigenverbrauchsoptimierung der Photovoltaikanlage durch Ladung des Brauchwasserboilers und der Wärmepumpe. Als nächstes möchte ich nun die Poolwasserheizung optimiert ansteuern, abhängig von der Stromproduktion der PVA und dazu brauche ich die Badwassertemperatur und die Möglichkeit die Umwälzpumpe anzusteuern.
Bevor ich die API-Kommunikation mit Node Red versuche muss ich sinnvollerweise den genauen Syntax zum Auslesen der Daten via API-Schnittstelle kennen. Mit dem Browser scheint es jedoch nicht zu funktionieren, ich hoffe noch, dass ich vom Lieferant ein Beispiel bekomme. Aktuell versuche ich ob ich mit Postman weiter komme.
-
@bugs sagte in Bestimmte Daten aus einer Webseite auslesen und steuern:
Irgendetwas mache ich anscheinend grundlegend falsch oder kann es sein, dass via Node ‚http request‘ mit der Methode ‚GET‘ eventuell die Webseite gar nicht ausgelesen werden kann oder wird in der Debugg-Spalte einfach nicht die gesamte Webseite (Quelltext) angezeigt?
Das ist NICHT dein Problem. Im Debug Fenster wird dir lediglich nicht die komplette site angezeigt. Die kann extrem lang sein, da würde es keinen Sinn machen. Aber natürlich wird sie im payload komplett weitergegeben.
Was du wohl im ersten Ansatz versucht hast ist "web scraping". Kann man zwar in node-red machen, dafür gibt es aber weit elegantere tools (z.B. puppeteer).
Es ist allemal besser die API zu nutzen. Beim scraping hast du immer das Problem, dass du evtl. im Regen stehst, wenn die site geändert wird. Die API bleibt dabei (i.d.R.) gleich.Falls du dich doch an web scraping mit NR versuchen willst, hier mal exemplarisch ein Bild, wo ich mal eben deinen letzten Beitrag aus dieser Seite hole.
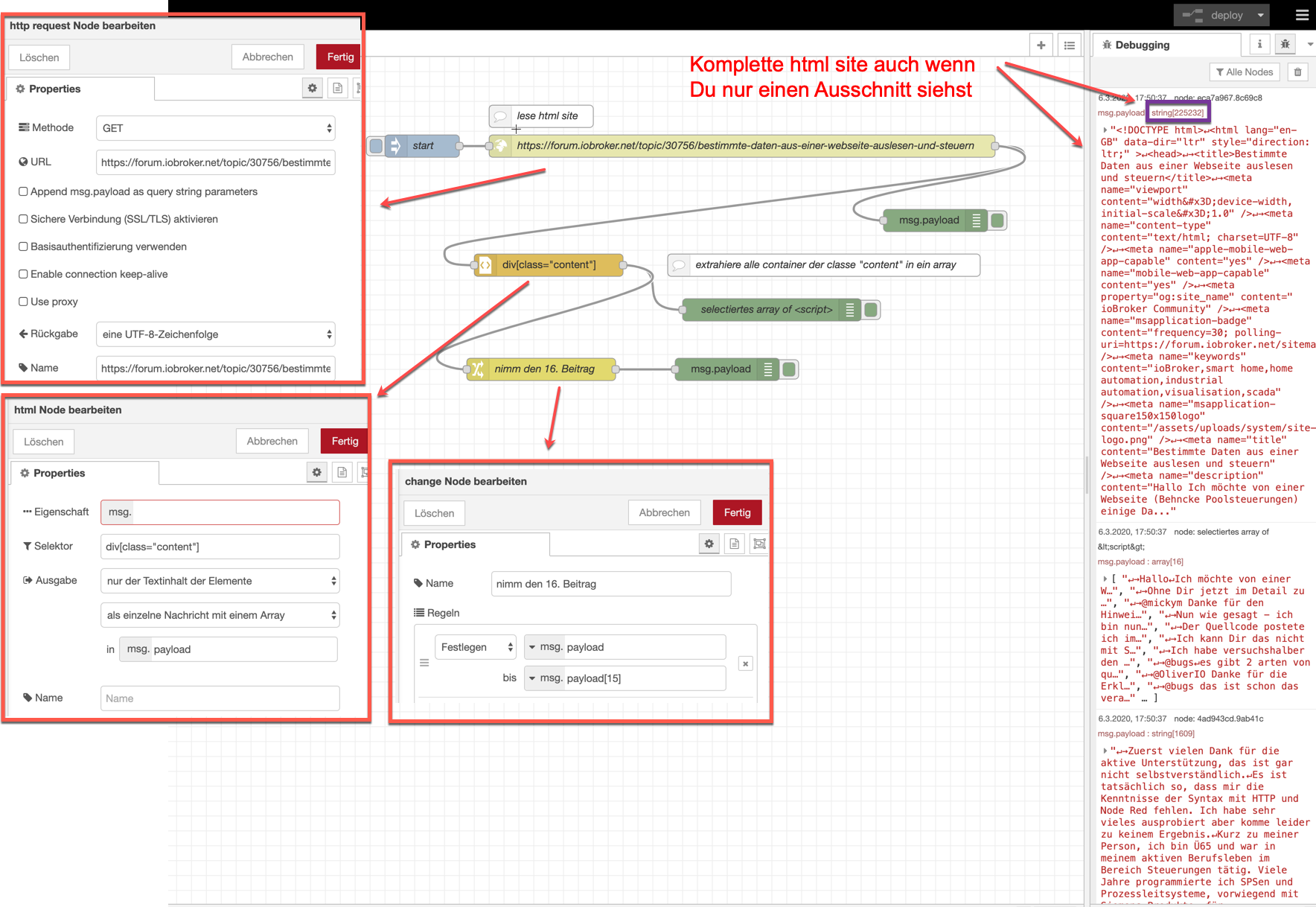
Wie du an die Selectoren kommst wurde hier ja schon beschrieben. Leider schluckt NR kein XPATH.
Die Standardsyntax für die CSS Selctoren findest du z.B. hier:
https://www.w3schools.com/cssref/css_selectors.asp@bugs sagte in Bestimmte Daten aus einer Webseite auslesen und steuern:
Kurz zu meiner Person, ich bin Ü65
Willkommen im Club

Nachtrag:
Und mit dem korrekten CSS-Selector gehts dann noch einfacher: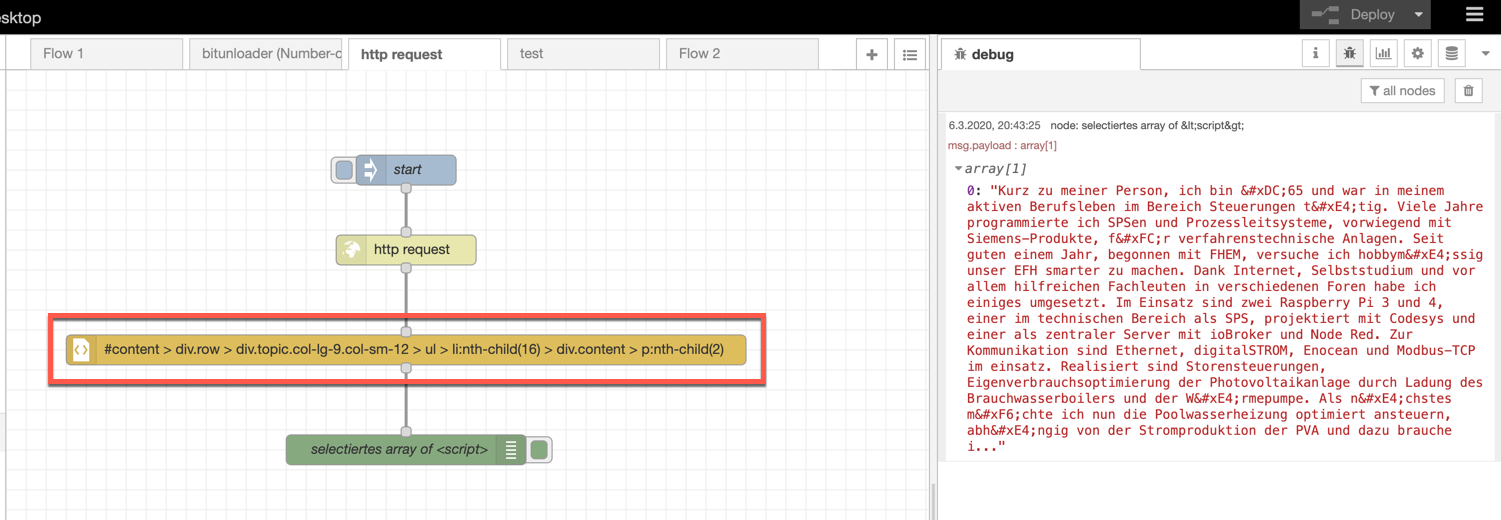
-
@rewenode Super, vielen Dank für den ausführlichen, aufwendigen Beitrag. Damit sollte sogar ich einen Schritt weiter kommen. Ich verfolge im Moment noch beide Lösungsvarianten mit und ohne API.
Dass nicht alle Daten im Debug Fenster sichtbar sind habe ich vermutet, unsicher war ich als auch die Daten von payload, gespeichert in ein File, nicht vollständig waren.
Wie entwickelt man so einen CSS-Selector? -
@bugs sagte in Bestimmte Daten aus einer Webseite auslesen und steuern:
Wie entwickelt man so einen CSS-Selector?
Entwickelt wird der eigentlich nicht. Vielmehr ergibt er sich aus der HTML-site. Er ist sozusagen die spezielle Syntax eines Zeigers auf ein spezielles Element innerhalb der html-site. (XPath ist eine alternative Syntax, die von NR allerdings nicht nativ unterstützt wird).
Du meinst sicher, wie man den korrekten CSS-Selector zu einem bestimmten html-Element findet. Und das kann recht tricky sein.-
selber machen
Am sichersten(aber aufwändigsten) ist natürlich den html-code in einen vernünftigen html-editor zu laden, und sich den CSS-Selector anhand der tags der html site gemäß der Sytax siehe https://www.w3schools.com/cssref/css_selectors.asp zusammenzustellen.
Hier kann man mal mit den Selectoren spielen und so ein Gefühl dafür bekommen:
https://www.w3schools.com/cssref/trysel.asp
Zum Prüfen, ob der selber erstellte Selektor dann korrekt ist, gibt es z.B. Online-Tools:
https://codepen.io/sunakujira1/pen/dMeKvV -
Eine viel einfachere Methode ist natürlich, sich den Selctor einfach von Browser ausspucken zu lassen. Hier empfehle ich chrome:
Dazu öffnest du die site in chrome und dann
chrome-menü -> Anzeigen -> Entwicker -> Elemente-Informationen
Jetzt die Maus auf das Element positionieren, dessen Selector du haben möchtest
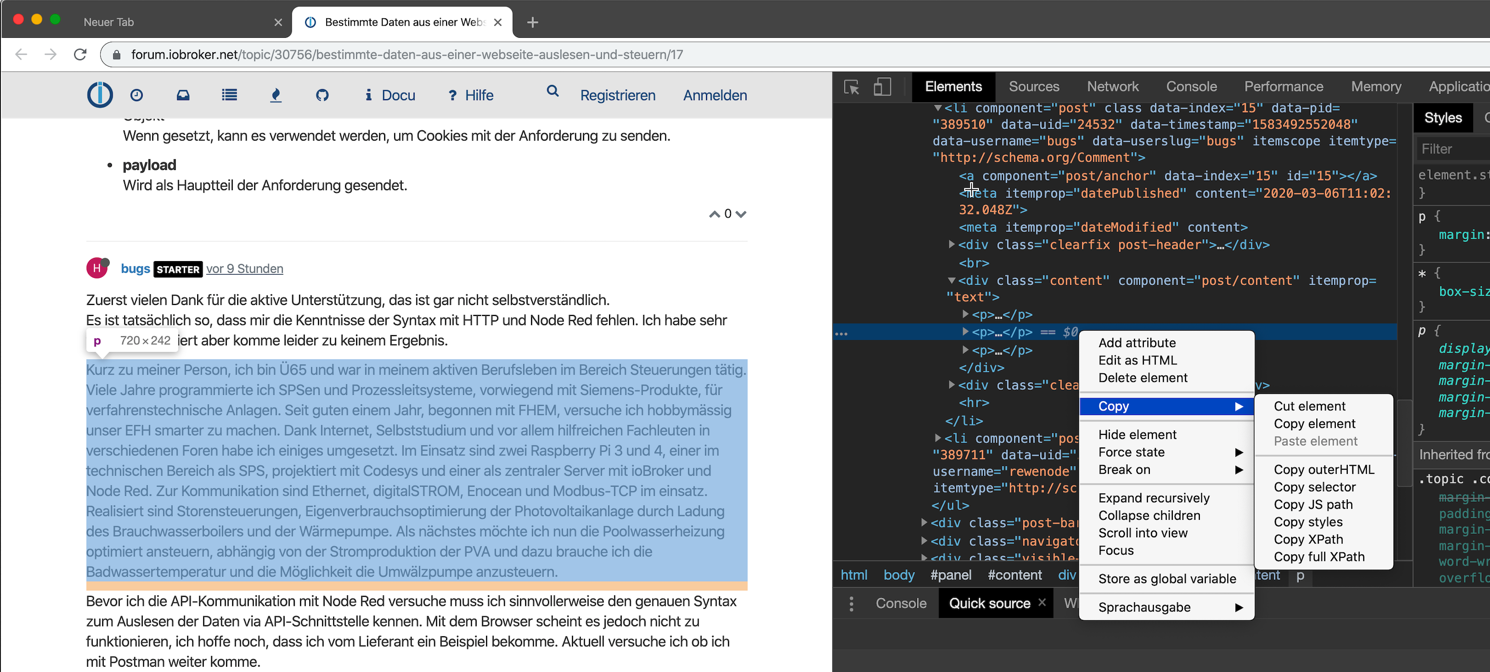
Rechts im Quelltextfenster ist dann das zugehörige tag markiert. Wenn es passt sollte links dein gesuchtes Element markiert und rechts das tag markiert sein.
Im Kontextmenü kannst du nun über "Copy Selector" den zugehörigen CSS-Selector kopieren und direkt als CSS-Selector im node-red html-node verwenden.Aaaber es gibt bei Methode 2 reichlich Tücken;-)
- Die Browser zeigen den Selector, der für die "angezeigte" site gilt! Das muss nicht der Selector der reinen html-Datei sein. Machst du z.B. das Browserfenster kleiner, gibt es i.d.R. Umbrüche bei einigen Elementen (Bildern/Tabellen) etc. Diese Umbrüche finden sich dann auch im Selector wieder, obwohl sie im Original-html nicht drin sind.
Mit anderen Worten, ein Browser rendert je nach Hersteller oder aktueller Ansicht eine html-site individuell und formatiert die site ggf. um. - Server liefern die html-site ggf. unterschiedlich aus, in Abhängigkeit davon, was für ein Browser da die site gerade anfordert. So kann er z.B. auf verschiedene Darstellungsmöglichkeiten des Browsers reagieren.
Tipp, nimm chrome der ist da noch am kompatibelsten.
Abschließend kann ich nur nochmal warnen. Web scraping hat immense Tücken und wird eigentlich nur angewendet:
- Wenn keine API vorhanden oder eingesetzt werden kann
- Wenn mal eben schnell was aus einer site extrahiert werden soll ohne dass das eine verlässliche Schnittstelle werden soll.
- oder man die site selber gebastelt hat und keine Lust hat, noch ne API zu definieren
schönes Wochenende
-
-
Da ich vom Lieferant betreffend API immer noch keine näheren Infos erhalten habe versuche ich die Daten via html und Selector herauszufiltern. Wenn ich jedoch mit Chrome-Entwicklertools unter Elements nach der Wassertemperatur suche kann ich diese nicht finden. Liegt das eventuell daran, dass der Server die Daten erst nach dem Durchlauf mit javascripts bereitstellt, so wie OliverO das im Beitrag vom 4.3.2020 15:14h beschreibt und deshalb die Daten garn nicht zur Verfügung stehen? Unter Sources sehe ich die Variable mit der Wassertemperatur.
So wie ich verstanden habe funktioniert das Prinzip via html-Site und Selector nur dann (meistens) richtig wenn die Daten (Aufbau der html-Site) immer gleich bleiben. Bei meiner Applikation möchte ich die Wassertemperatur herauslesen und dieser Wert ändert sich logischerweise. Ist es denkbar den String, welcher die Wassertemperatur beinhaltet mit einem Selector zur filtern und anschliessend mit String-Manipulationen eventuell mit RegEx den Wert der Wassertemperatur zu separieren oder funktioniert der Selector nicht mehr richtig sobald sich der Zahlenwert der Wassertemperatur ändert?
@rewenode
Kann es sein, dass mit dem neusten Node Red V1.0.3 XPath funktioniert, egal ob ich mit selector arbeite oder mit XPath oder full XPath erhalte ich die gleichen Ergebnisse.Für die definitive Lösung werde ich versuchen die API-Schnittstelle zu nutzen.
Ist das richtig, dass API-Schnittstellen (REST-API siehe auch Beitrag vom 5.3.2020 12:49h) nicht generell syntaktisch gleich aufgebaut sind, sondern je nachdem wie diese programmiert wurden unterschiedlich sein können und somit eine genaue Beschreibung der zu verwendenden API-Schnittstelle notwendig ist? Einige Versuche mit Postman blieben bis jetzt erfolglos.
