Journal-Log erstellen
-
So mit dem Teil2 kommen wir also zur Verarbeitung - nachdem Du nun events und Datum hast - kannst Du einzelne Nachrichten wegschmeissen herausfilter usw.
Nach der Verarbeitung (der einzelnen Events) - schmeißen wir alle wieder zusammen in ein Array. Das macht die JOIN Node.
Man kann ihr entweder über einen trigger mitteilen wann das Array fertig ist (msg.complete = true) - ich habe hier der Einfachheit mal ein Zeitlimit eingegeben - da mein Log in der Regel selbst wenn es groß ist, in 10 Minuten eingelesen ist.
Wir haben also nur noch eine Nachricht - die alle Events in einem Array in einer Payload enthält.
Ich hoffe Du folgst mir - ich versuche es ja mit Screenshots immer zu erklären:
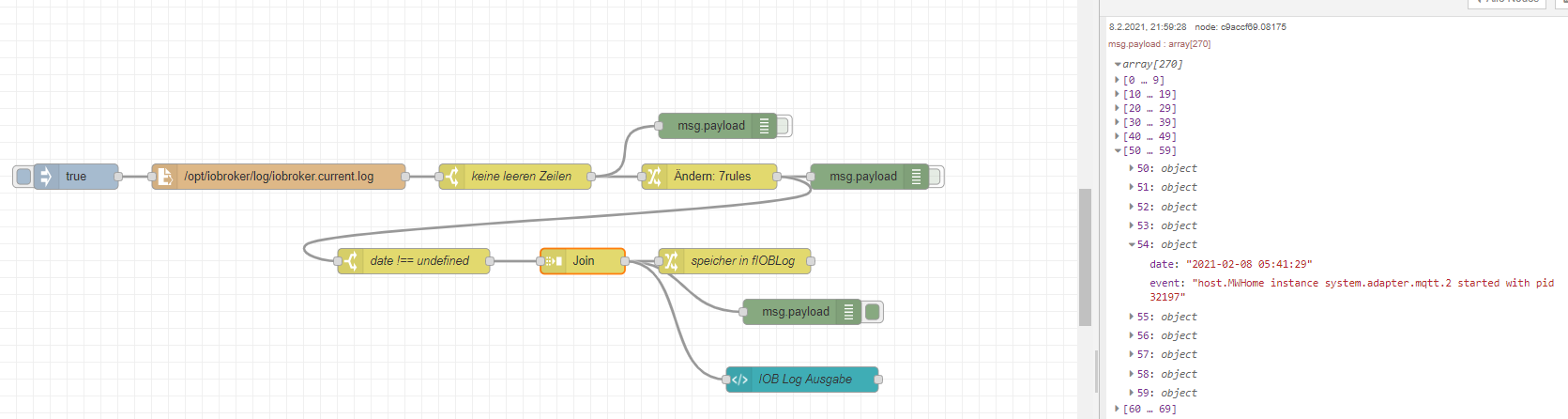
So ein Array kannst Du dann auch in einer flow Variablen speichern und ggf. getriggert für weitere Untersuchungen verwenden. Das macht die 2. Change Node - die aber sonst keine Aufgabe hat - außer die Payload - das Array in einer Variablen zu speichern.
Im Kontext Menü sieht das dann so aus.

Die Ausgabe erfolgt im 3. Teil.
-
So nun zur Ausgabe (Teil3 )- ich bin leider kein HTML Programmierer - da gibts hier viel fittere Leute an Board und ich hab das für Dich nur mal schnell so quick & dirty hingebastelt. Du magst Dich vielleicht fragen, warum ich das Ganze in ein Array gepackt habe.
Node Red hat die tolle Eigenschaft auch in dem Dashboard dass die Angular JS unterstützt wird.
Wie Du hier ja selbst angemerkt hast - eignet sich hier für die Ausgabe die Template Node am Besten:
Neben dem ganzen Formatierung ist das Geniale diese ng-repeat Direktive (alles verlinkt hier).
Im Quelltext kannst Du nämlich mit ein paar läppischen Zeilen durch das ganze Array durchgehen.
Das ist nämlich dann alles - was Du zur Ausgabe des Logs brauchst.
")
<div class="main"> <table id="t01"> <tr><th width=20%>Datum</th><th width=70%>Event</th></tr> <tr ng-repeat="item in msg.payload"> <td align=left>{{item.date}}</td><td align=left>{{item.event}}</td> </tr> </table> </div>Alles ist bei mir nicht schön rausgekommen aber zur Verdeutlichung langt es - also hier nun das iobroker Log als HTML Tabelle im Node Red Dashboard:
Wie gesagt - das geht alles viel schöner
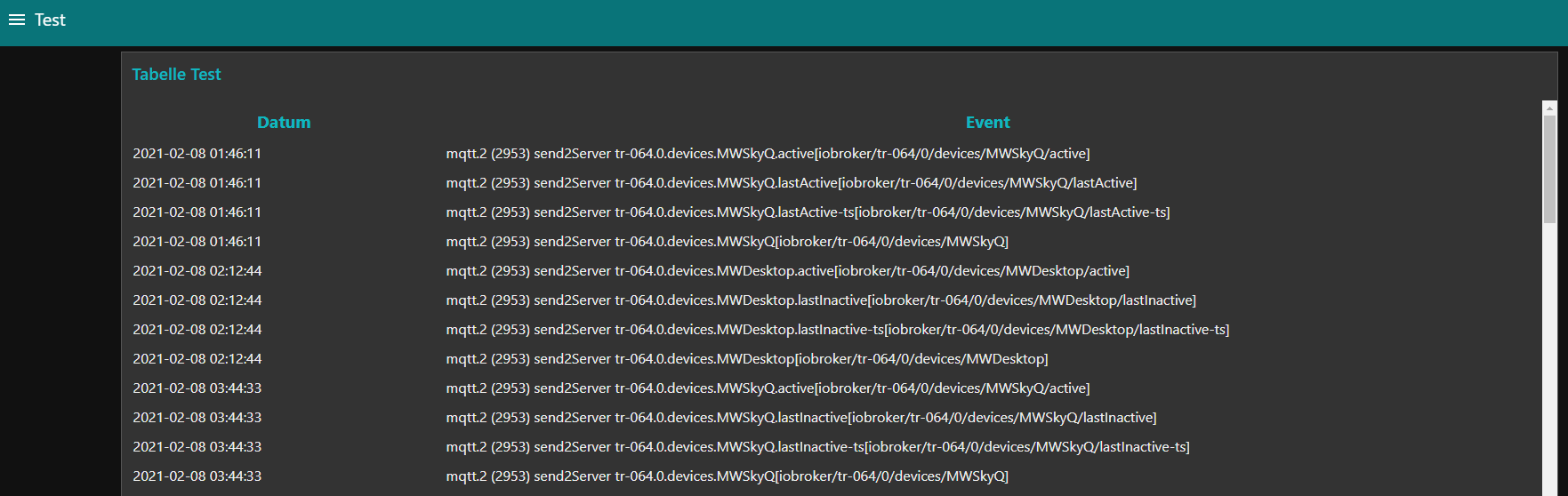
Also keine Fragen zur HTML Formatierung bitte - das können hier andere an Board viel besser.
-
Teil4 - so wie gesagt, warum ich NodeRed liebe - das Ganze hier ist bis auf den Code der HTML Formatierung mit wenigen Nodes erledigt:

und erfordert quasi 0 Programmierung.
Alles mit Standard-Nodes und ohne Function-Nodes mit irgendwelchen Programmzeilen. Hier der Flow zum Importieren und Spielen - die wichtigsten Dinge habe ich ja nun erklärt:
Als Hilfsmittel zum Analysieren Deiner Logdatein eignen sich wie ja hier schon erwähnt die regulären Ausdrücke gut.
Ich teste immer hier - da sieht man dann auch was in den Gruppe $1 usw. entahlten ist. https://regexr.com/
Ansonsten fragen, warum ich was gemacht habe - aber nun bist Du am Zug - Deine Wünsche zu realisieren.
Neue Logzeilen hängst Du einfach an das Array an usw. Um Tabellen in Spalten zu sortieren, wie gesagt dass können Dir HTML Programmieren sicher besser erklären - bzw. im Moment weiß ich sowas einfach nicht.
-
So noch ein paar Ergänzungen:
Die tail-Node ist hervorragend, da sie ja aus sich selbst herausgetriggert wird und immer die letzte Zeile ausgibt.
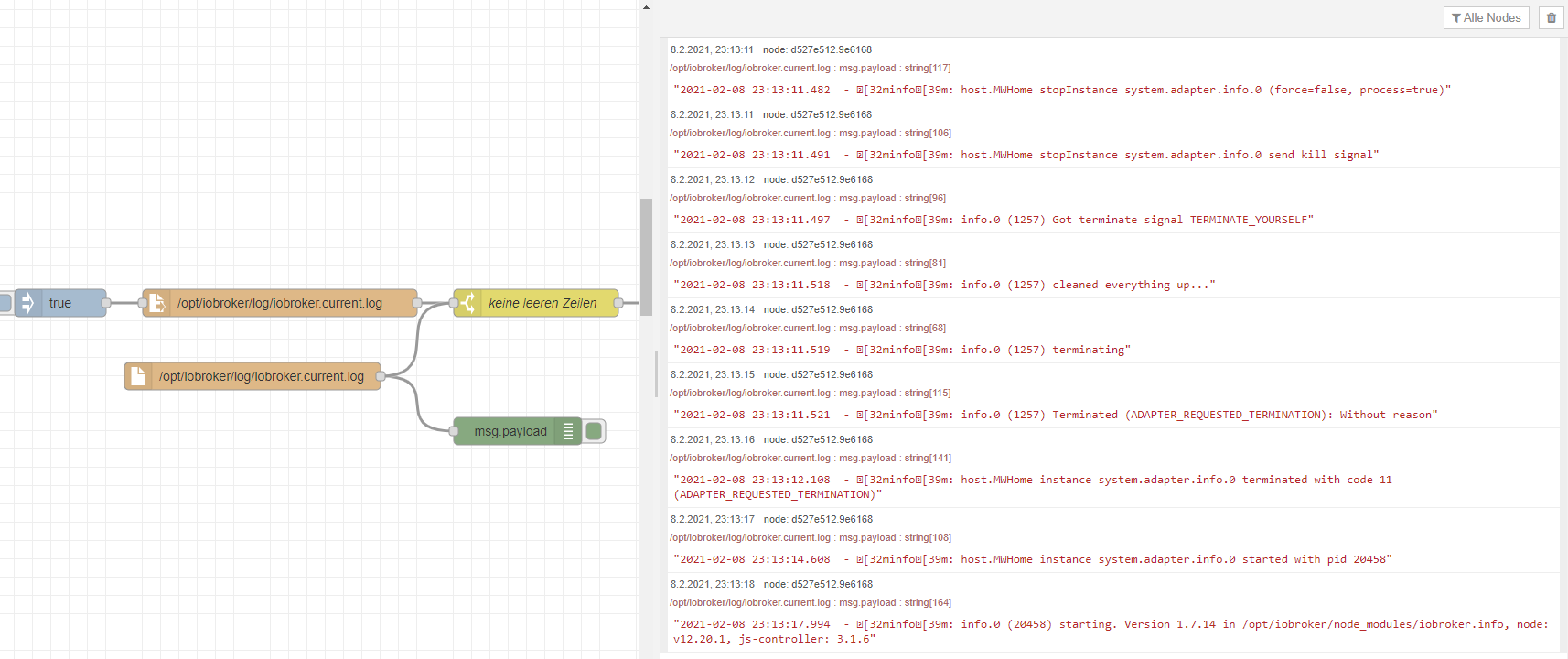
Wenn man die Join-Node kann man nun natürlich so konfigurieren - dass sie anstelle von 10 sekunden - das Array erst nach 300s bildet - dann bildet sie das Array erst nach 300s und zusammen mit der Tailnode habe ich nur die Einträge der letzten 5 Minuten drin.
Oder ich konfigurieren die JOIN Node so, dass sie auf einen externen Trigger reagiert habe ich folgenden mit einem Inject Node dargestellt. Der kann entweder zyklisch ablaufen - das LOG wird mit jedem neuen Array ja gelöscht. Im Prinzip kann man natürlich statt der JOIN Node eine Function Node machen und im Function Node Kontext das Array aufbauen. Das wird dann nicht mehr gelöscht und man hängt mit Array.push jede payload hinten dran. Ausgegeben wird das ganze Array wieder via trigger.
So kann statt der Inject Node ja einfach die uicontrol Node dienen, die dann triggert wenn Du die entsprechende Seite in Deinem Dashboard öffnest.
Also mir fallen 1000 Dinge ein.
Das ist zum Beispiel die Ausgabe mit der TAIL Node - nachdem ich die JOIN Node auf 300s gestellt habe und in der Zwischenzeit den Info-Adapter neu gestartet habe.
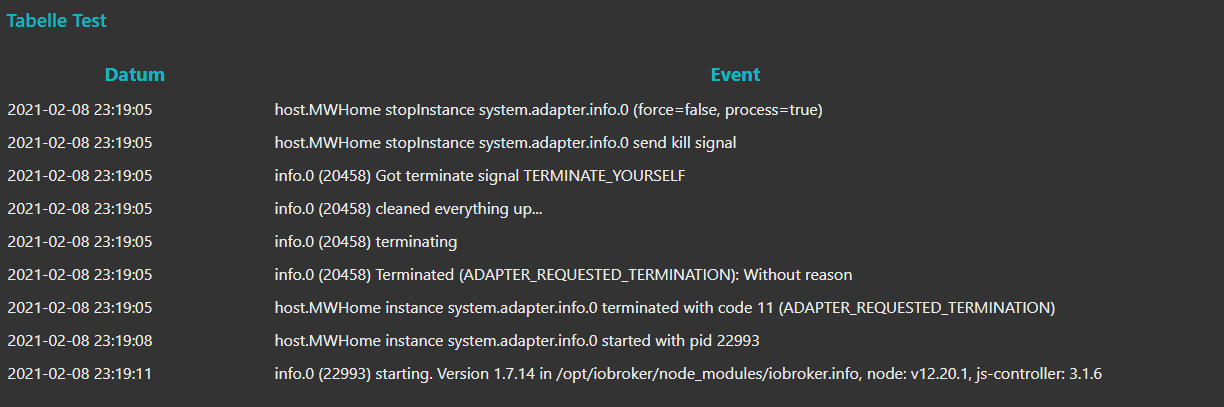
Mit msg.complete als trigger kann man das auch vorher ausgeben, selbst wenn das Zeitintervall noch nicht abgelaufen ist.
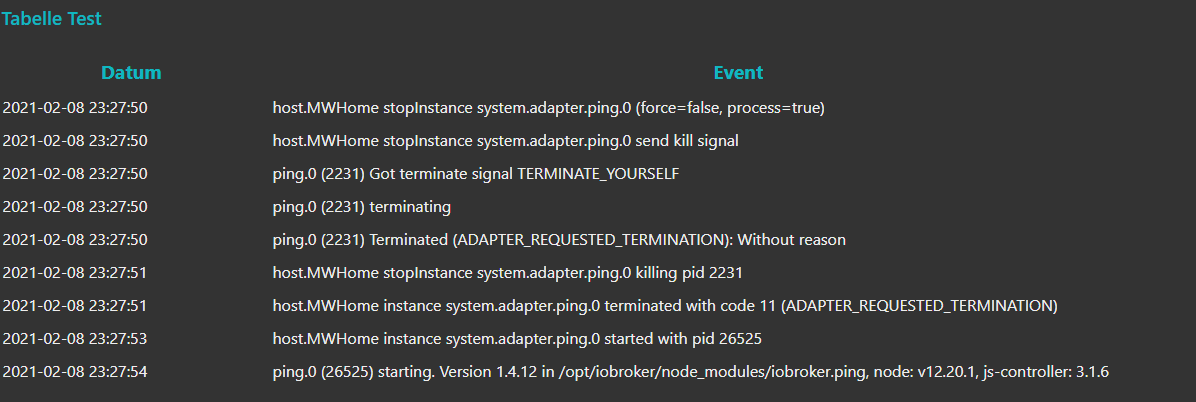

Also den Möglichkeiten sind kaum Grenzen gesetzt. Der Inject Node kann wie gesagt selbst als Trigger dienen nicht nur manuell:
Hier mal die Ausgabe des Logs im 15 Minuten Intervall:
-
@tomily Also in Summe war Dein Ansatz mit der Tail Node GOLDRICHTIG. Das nur die letzte Zeile genommen wird, ist ebenfalls aus Sicht der Entwickler richtig. Für die Speicherung mehrerer Nachrichten bist Du selbst verantwortlich. Anstelle von Zeitintervallen kannst Du den JOIN Node auch so konfigurieren, dass er erst nach 50 Nachrichten, dass Array ausgibt - das muss also nicht zeitabhängig sein.
Im Übrigen dient dieser Flow mit der tail-Node auch hervorragend dazu bei bestimmten LOG-Einträgen weitere Flows zu triggern. Nur mal so als Anmerkung/Anregung.
Eine Möglichkeit wäre ebenfalls die Ausgabe anhand einer Zeit/Datums oder aber bei einem bestimmten Ereignis auszugeben. So könnte auch ohne Datenpunkt ein Blockly einen LOG Eintrag erzeugen, der einen Flow in NodeRed anst ... 

und zum Schreiben eigener Log-Dateien gibts die FileNode. - Die ist auch schon im Standard enthalten.
-
Weil es mir einfach keine Ruhe gelassen hat.
Du kannst natürlich sämtliche Logeinträge in Echtzeit ausgeben, dazu muss sowieso immer das ganze Array ausgegeben werden. Die JOIN Node löscht das Array ja jedesmal, wenn sie eine Nachricht ausgibt (zumindest in dieser Konfiguration).Deshalb mal schnell eine Function Node - die soviele Logeinträge ausgibst bist Du einen Clear Trigger setzt. Alternative kannst Du natürlich in Function-Node auch selbstständig eine Löschung vornehmen. Beispiele wären rollierende Logs nach Zeit oder Anzahl von Einträgen durch eine events.shift() Anweisung. Das würde dann Deiner Anforderung entsprechen, nur die letzten x Einträge zu sehen, indem man die Anzahl der Elemente in dem Array konstant hält.
Also für 50 Einträge könnte man dann so was machen:if (events.length > 50) events.shift();Wenn man das nach der push Anweisung einfügt, dann wird halt beim 51. Eintrag der 1. (=älteste) gelöscht und damit hättest Du das mit den 50 neuesten Einträgen.
Wichtig ist nur, dass Du weißt - wenn Du das auf dem iobroker Log alles ausprobierst und Du hast einen Fehler in dieser Function Node - oder generell in NodeRed wirft eine Node einen Fehler - dann produzierst Du mit der Tail-Node ganz schnell eine Endlosschleife. Also ggf. NodeRed Ereignisse alle verwerfen bzw. ausfiltern. Das kannst aber selbst dann checken. Ich habe das zur Sicherheit hier nochmal gemacht.
Hier mal der Inhalt der Function Node:
var events=context.get('events')||[]; events.push(msg.payload); if (msg.clear){ events = []; } context.set('events',events); msg.payload = events; return msg;In diesem Fall - doch mal eine Function Node - und ein paar Programmierzeilen.
- Sollte aber die Ausnahme bleiben. Und hier nochmal der komplette Flow mit der function Node:
Außerdem habe ich noch festegestellt wenn die Nachrichten zu schnell einlaufen, wird die Anzeige ggf. auch nicht mehr korrekt - dann halt noch eine delay Node dazwischen schalten.
-
@tomily So und nun noch das Non-Plus Ultra - weil wir eh schon das Array haben. Hier gibst eine Tabellen Node für das Dashboard.
Das Array haben wir schon - und damit kann man dann auch in Spalten sortieren.
https://flows.nodered.org/node/node-red-node-ui-table
Ich habe es schnell mal installiert ist super Klasse.
Die Table Node einfach an die function Node hängen:

Output kann in den Spalten sortiert werden und diese Standardansicht gibts ohne besondere Konfig:
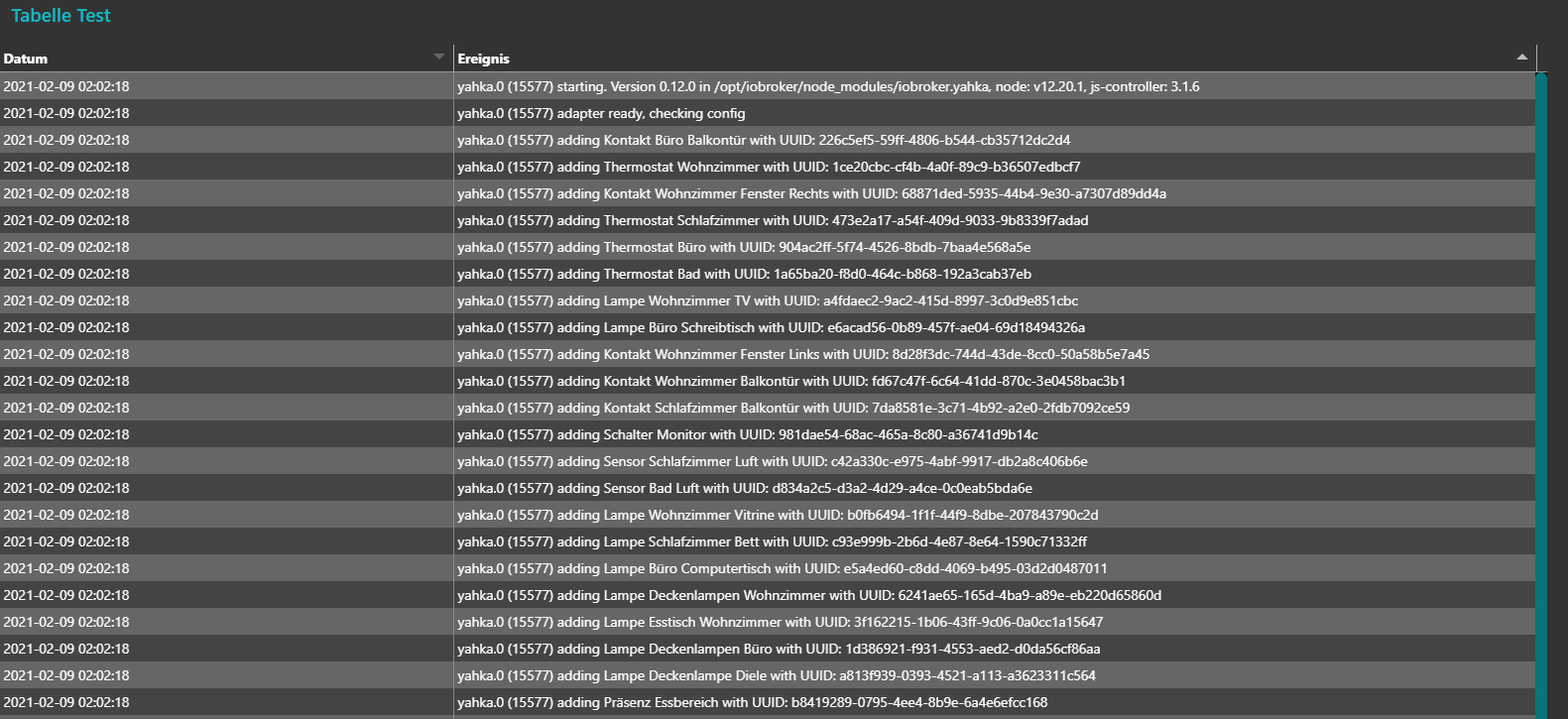
Das Einzige was man eingeben muss sind die Spalten und wie die in den Objekten heißen:
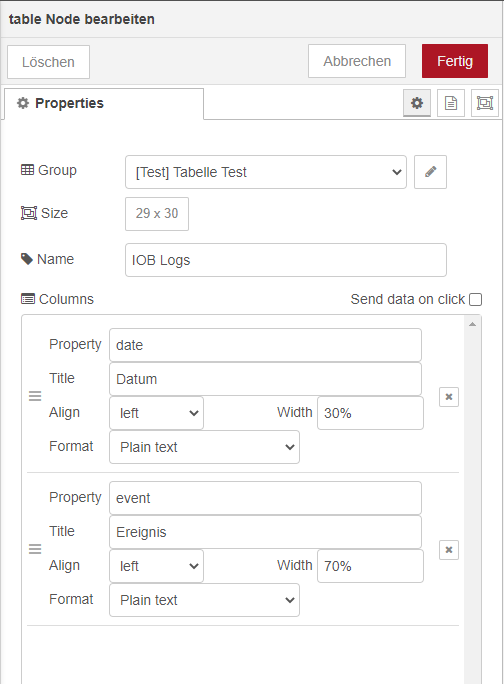
Zur Standardisierung des Datums bei anderen Logdateien - würde ich schauen, dass Du es genauso hinbekommst wie im iobroker - da dies das standardisierte moments.js Format ist und ggf. in ein von Dir gewünschtes einheitlich umformatiert werden kann. Bleiben die Logs alle innerhalb eines Tages funktioniert das sortieren dann auch, wenn z.Bsp. Text im Datum ist.
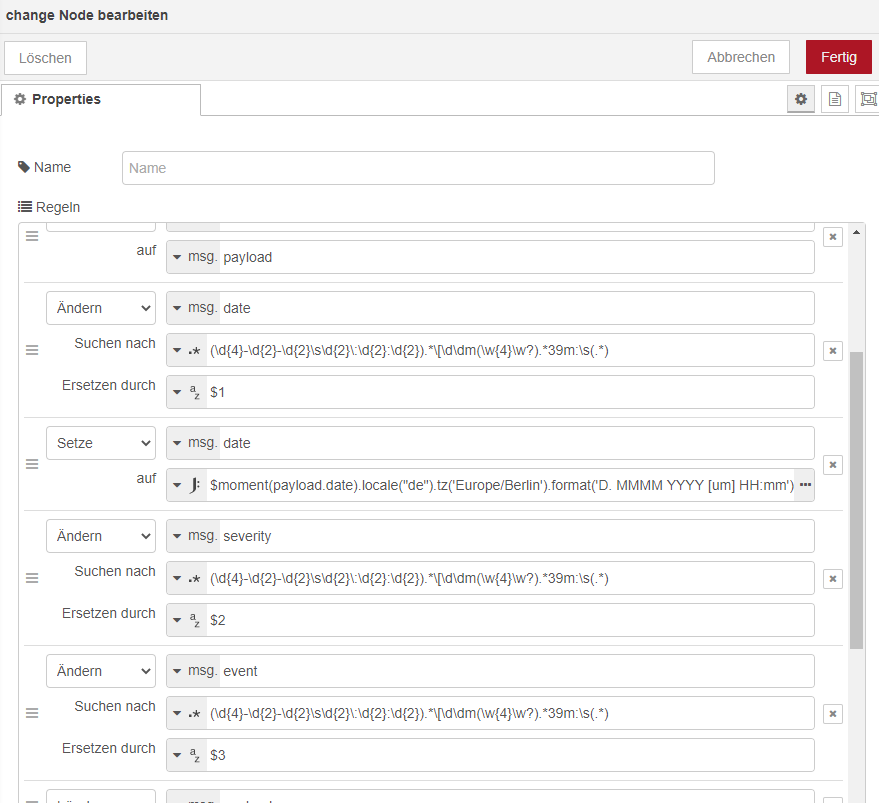
Das ganze mit dem Datumsformaten und dass dies auch von den Change Nodes beherrscht wird - wurde ja schon mal hier diskutiert. Mit einer aufgebohrten Change Node:kannst Du dann das Datumsformat jeder Logdatei für Dich anpassen:

So ich habe noch etwas rumgespielt. Wenn man aus dem iobroker Log noch die Severity herausliest - dann bekommt man dieses Objekt:
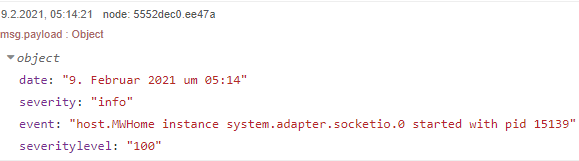
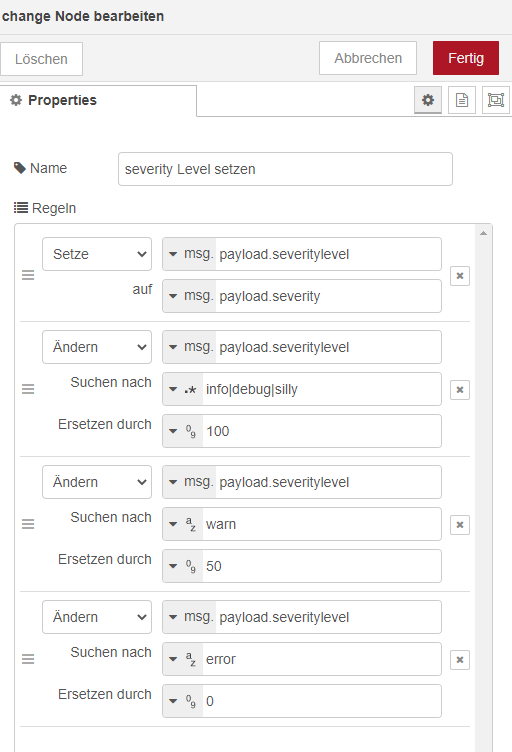
Den Werten kann man nun im serveritylevel - Zahlenwerte zuordnen. Ich habe mal debug, silly und info 100 zugeordnet, warn 50 und error 0. Das würde man über einen Change Node dann so machen.
Die veränderten Change Nodes hier (wegen der geöffnet Klammer kann man das leider nicht wieder importieren, deshalb als Screenshot:
In dieser neuen Tabellenfunktion kann man dann den Zahlenwerten automatisch Ampelfarben zuordnen:

Das schaut doch auf die Schnelle ziemlich brauchbar aus.
In Summe wirst brauchst Du also nichts weiter machen müssen, als für jede zu überwachende Log-Datei eine Tail-Node zu konfigurieren, die Logeinträge über reguläre Ausdrücke zu standardisieren, der Function Node übergeben und in der Tabelle ausgeben und/oder parallel in eine eigene Logdatei zu schreiben.
-
@mickym
WOW! Ich bin beeindruckt von so viel Aktivität, Kompetenz und Geschwindigkeit.
Ihr seid ja alle der Hammer.DANKE für die Lösung von Dir mickym. Die Flows sind alle mit den Node-Red Bordmitteln und geben das Log im endeffekt so aus wie ich das wollte
")
Hat nach dem importieren sofort funktioniert. Werde das mal noch versuchen auf mein eigenes Log anzuwenden, damit auch das voll läuft.Da ich kein großer und guter Scripter bin, werde ich mir die Scripting-Vorschläge auf jeden Fall anschauen. Fürchte aber, dass die Regex und andere Geschichten mich überfordern.
Zunächst nochmal Herzlichen Dank. Melde mich gerne nochmal nach erfolgreichem Test zurück

-
@tomily Das freut mich natürlich, wenn es so klappt, wie Du Dir das vorgestellt hast. Ich mache das ja gerne, weil ich selbst daran lerne und auch mit vorhandenen Kenntnissen, diese anders anzuwenden, als ich das heute bereits tue.
Ich mache inzwischen ja kein Hehl mehr daraus, dass ich inzwischen ein großer NR-Fan bin und man, wenn man das Prinzip verstanden hat, mit quasi kaum Programmierkenntnissen einiges erreichen kann. Jedenfalls bin ich der Meinung, dass man bei blockly mehr Kenntnisse benötigt und für mich ist es eben auch nicht so intuitiv - da ich immer nach den entsprechenden Puzzlestückchen suchen muss und meist nie finde.
Die ganze Arbeit ist mit ca. 5-6 Nodes getan und auch die function Node ist nicht besonders aufwändig programmiert. In Kombination mit dem iobroker hat man halt in meinen Augen 2 Systeme, die sich ideal mit Ihren Stärken ergänzen. Das NR war - habe ich glaube schon früher mal geschrieben - von der IBM eine kommerzielles Produkt, was dann aber wohl freigegeben wurde. So genau weiß ich das nicht. Die Nodes jedenfalls sind mit Adaptern des iobrokers zu vergleichen - ich versuche gerade selbst welche zur Anbindung an den iobroker über socket.io zu entwickeln. Die Community hierzu ist deshalb noch wesentlich größer als IOB.
NR hat jedoch überhaupt keine brauchbare Methode, die Zustände also die Datenbank anzuzeigen und zu verwalten. Für reine NR Benutzer war zu diesem Zweck MQTT - als Broker und Datenverwalter vorgesehen. Das ist auch der Grund, warum dieses Protokoll soviele Geräte benutzen. Hierfür hast Du dann aber wieder Drittmittel gebraucht, um das vernünftig anzuzeigen. Von solchen Features wie Aliases etc. ganz zu schweigen - das sind die wirklichen Stärken des IOB.
Mein Ziel war es ja außerdem, quasi Hilfe zur Selbsthilfe zu vermitteln. Dir nicht einfach nur den Flow zur Verfügung zu stellen, sondern auch herzuleiten, wie ich/man so eine Lösung entwickeln kann. Dazu darf man oft nicht den Blick auf das Ganze verlieren. Das ist manchmal schwierig - aber mir macht es auch manchmal Spaß zu erkennen, was man selbst für ein Brett vor dem Kopf hat.
Beispiel: Du warst mit der Tail-Node, wie ich beschrieb schon auf dem richtigen Weg. Dieser Thread zeigt so eine Entwicklung in meinen Augen hervorragend. Dann hast Du Dich geärgert, dass die Tail-Node immer nur die letzte Zeile ausspuckt. Anstelle darüber nachzudenken, warum es vielleicht sinnvoll sein könnte nur 1 Zeile auszugeben, war nun Dein nächster Schritt eine Lösung zu suchen, mehrere Zeilen aus einem Log auszulesen, anstelle diese Zeilen eben in NR zu einem größeren Ganzen zu entwickeln. Dabei entlastet Dich NR ja gerade wegen der "Kleinheit" der Information. Einen größeren Informationsblock muss man mit Schleifen zerhacken, um letztlich eine Zeile in seine Bedeutungsbestandteile zu zerlegen und das wurde Dir abgenommen. NR ist ein Flow Tool - ich stelle mir immer vor, ich wäre eine payload und müsste mich durch die Nodes bewegen. Wenn ich also die letzte Zeile eines Logs wäre, dann wäre mein Ziel ja - nach der Aufgabenstellung - mal irgendwo in einer Tabelle als Klartext aufzutauchen - neben Geschwistern. Das sich für eine Ausgabe von Events ein Array anbietet durch das man einfach "durchiterieren" also durchzählen kann, hätte Dich vielleicht darauf gebracht, das Große zu sehen und hättest Dich nicht so sehr auf 50 Zeilen LOG lesen konzentriert.
Ich hoffe es ist OK, wenn ich das mal so ausführlich schreibe.
Noch ein Wort zu den regulären Ausdrücken. Ich habe diese kryptischen Dinge gehasst, wie die Pest und bin da heute noch manchmal am fluchen. Deswegen habe ich Dir die Seite gepostet, die mir ungemein hilft.
Trotzdem hier mal ein kleines Tutorial:
Ich werde es nochmals am iobroker Log versuchen zu verdeutlichen, damit Du es auf die anderen Logs anwenden kannst.
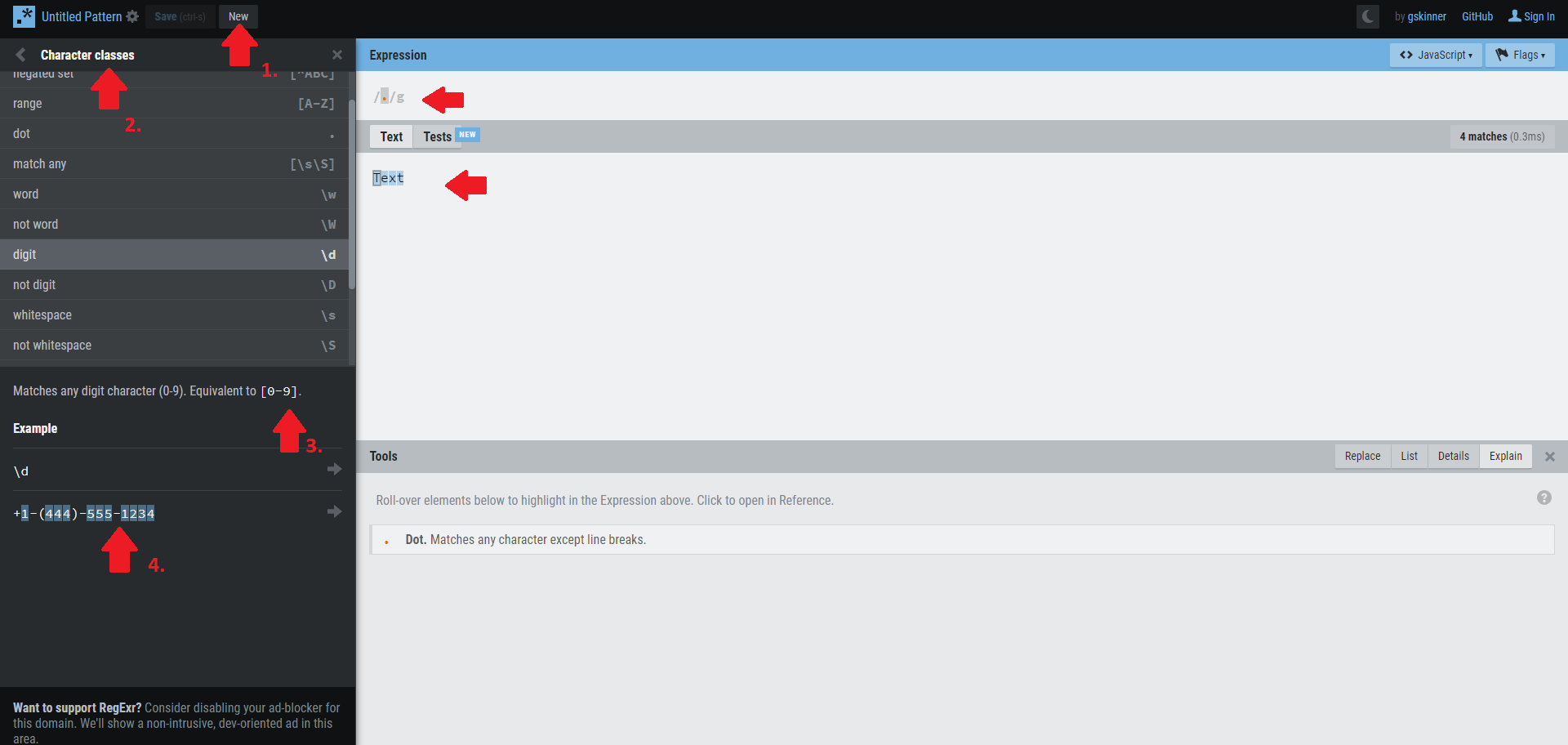
Dann drückst Du als erstes Mal den "New" button.Am Anfang muss man sich etwas auf der Seite zu Recht finden:
-
Mit New - machst Du erstmal alles "clean" auf der Seite.
-
Das zeigt schon aufgeklappt die Zeichenklassen.
-
Ich habe mal als Beispiel \d für eine Zahl ausgewählt. Das heißt der regEx Ausdruck matched wenn er eine Zahl finden. Hier im Thread haben die Kollegen [0-9] genommen, das ist das Gleiche wie \d. Im Prinzip ist alles was Du in eckige Klammern packst, maßgebend für 1 Match. Wenn Du also [123] oder [1-3] gibst, dann muss der String oder die Zeichenfolge eben eine 1,2 oder 3 enthalten damit das matched. Man kann auch beliebiges kombinieren [123abc], dann gäbe es einen Match bei 1,2,3 oder a,b,c und zwar nicht als 1 Wort, sondern als 1 Zeichen als Auswahl aus dem was in den Klammern steht.
-
Anhand des Beispielstrings siehst Du dann wie oft \d matched. Also dort 11 mal. Eine Regel für Dich muss später sein, dass ein Ausdruck genau EINMAL matched - nur so bekommst Du Eindeutigkeit.
5 und 6. Dann sind noch die Quantifiers wichtig. Ein Punkt '.', wie zu Beginn vorgegeben steht für ein beliebiges Zeichen. Egal ob sichtbar oder nicht, ob Zahl Buchstabe etc. Wenn man New gedrückt hat, sieht man dass jedes der 4 Zeichen (da ja beliebiges Zeichen) matched. Also steht rechts (4 matches). Ausserdem siehst Du um jedes Muster, das matched ein blaues Quadrat. Der Quantifier gibt an wie oft man das vorhergehende Zeichen wiederholen muss, damit ein match erfolgt.
-
Wenn Du also in dem RegEx nach dem Punkt einen * schreibst, was soviel bedeutet, dass das beliebige Zeichen - beliebig oft auftreten darf zu einem Match, dann siehst Du in
-
das nun nicht mehr jeder einzelne Buchstabe mit einem blauen Quadrat umrandet ist, sondern das ganze Wort.
-
Allerdings ist das nicht zu verwenden, da dieser regEx Ausdruck auf alles zutrifft und somit sinnlos ist - deswegen gibt es rechts die Warnung.

- Um es spezifisch zu machen - kann man nun sagen es soll matchen wenn in der Zeichenfolge ein T gefolgt von beliebig vielen Zeichen folgt.

Du siehst 1 Match - was in der Regel das Ziel ist.
-
Wenn man nur auf die Existenz von einem Zeichen oder einer bestimmten Zeichenfolge aus ist, dann ist es egal wie oft es matched ansonsten aber immer schauen dass es einmal matched.

-
So nun zu Deinen anderen Logdateien. Ich demonstriere es nochmal am iobroker Log.
Kopiere einfach eine Zeile in das Textfeld - nachdem Du "New" gedrückt hast.
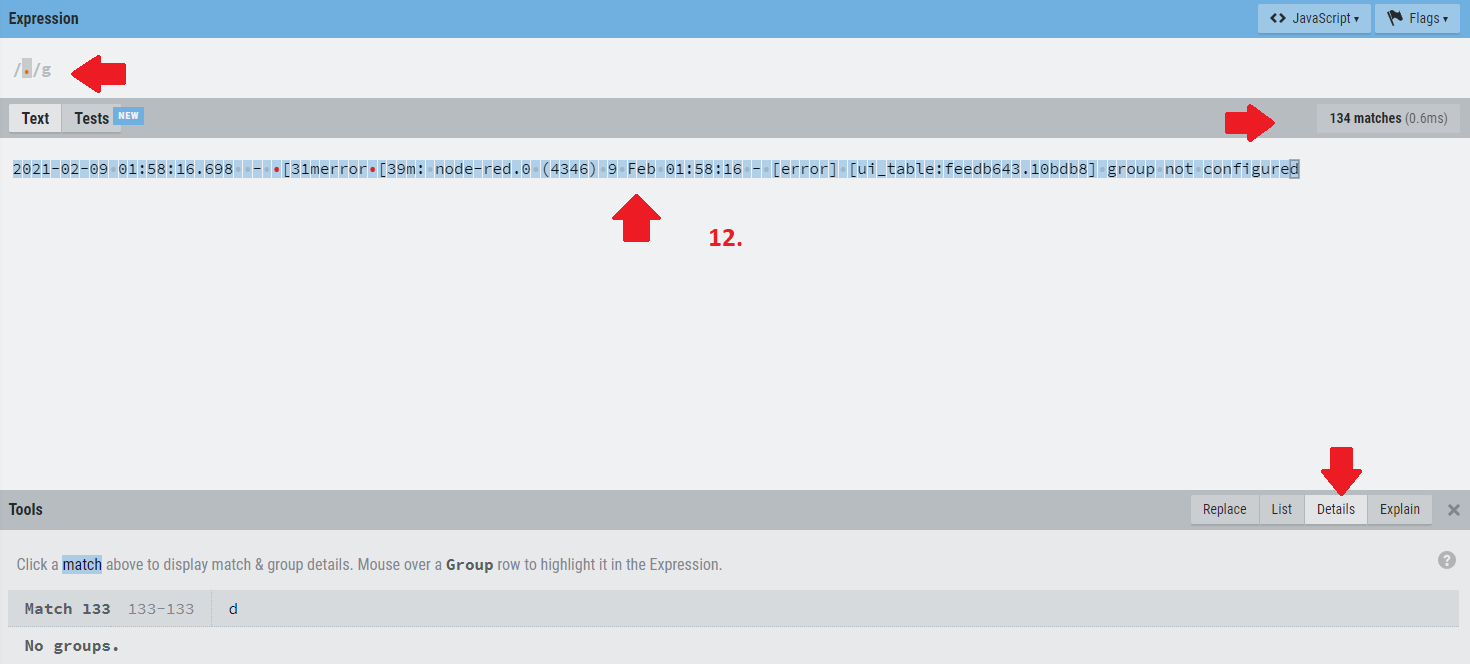
Du siehst mit dem '.' alleine hast Du 134 matches und dann klicke unten auf Details. Ich kopiere jetzt die regEX da rein, die ich in den Change Nodes verwendet habe. Alles was in runden Klammern steht bildet Gruppen die Du von links nach rechts mit $1, $2, $3 referenzieren kannst.
Wenn Du also folgenden Ausdruck oben reinkopierst, dann erhältst Du folgende Ausgabe im Detailfenster:
(\d{4}-\d{2}-\d{2}\s\d{2}\:\d{2}:\d{2}).*[\d\dm(\w{4}\w?).*39m:\s(.*)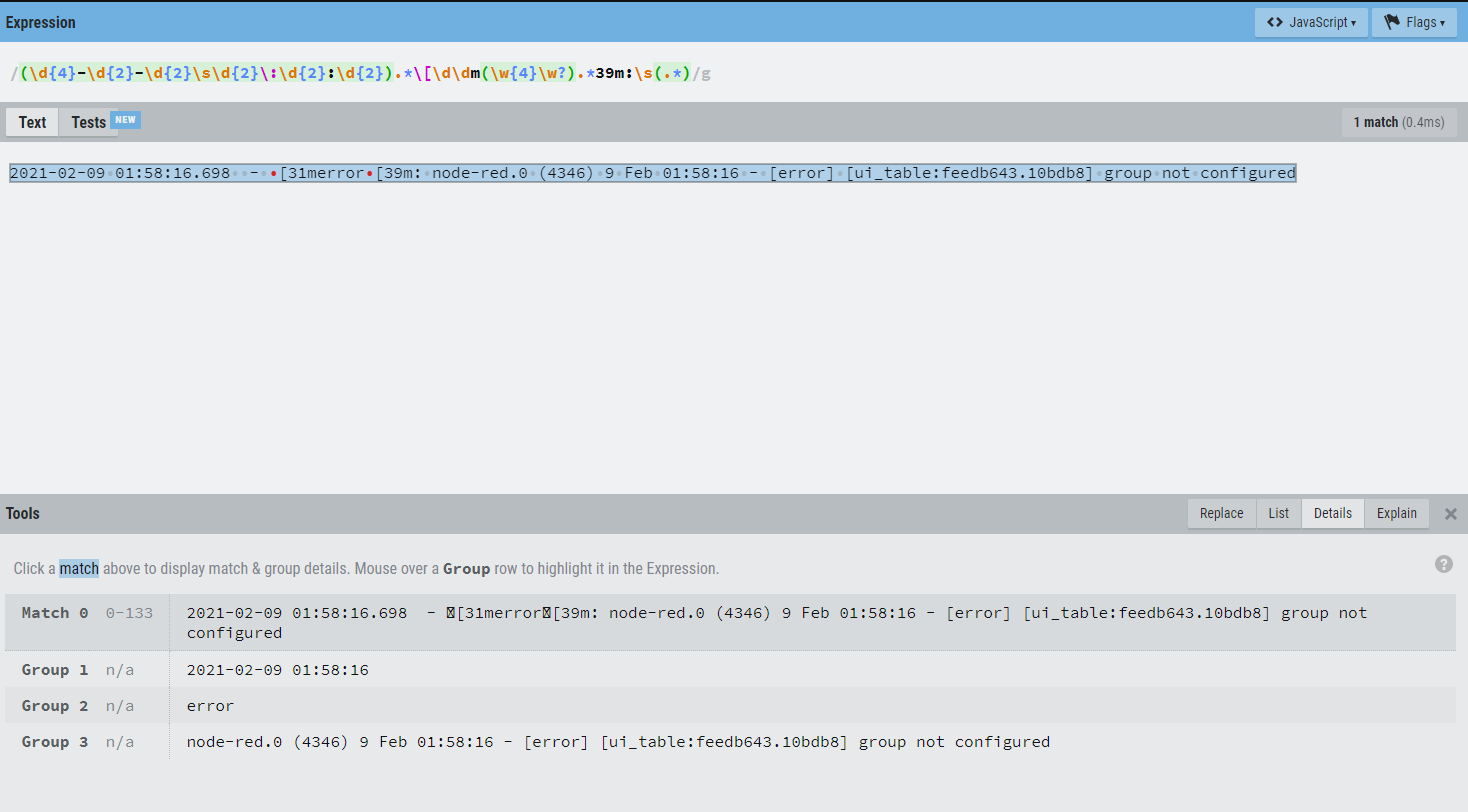
1 Match für die Eindeutigkeit und dann siehst Du wie ich aus einer Logzeile über die Gruppe 1 = $1, den Zeitstempel, die Gruppe 2 die Severty und mit der Gruppe 3 den Rest aus der Zeile analysiere.
So ich hoffe diese kleine Tutorial nimmt Dir bisschen die Angst vor regulären Ausdrücken und hilft Dir Deine übrigen Logdateien zu analysieren.
-
-
@mickym
Lieber mickym.Erst mal sorry für die späte Antwort. Ich betreibe das als Hobby und komme nicht immer sofort zum antworten und testen.
Ein ganz arg fettes DANKE für deine Rückmeldung. Das ist ja schon eine richtige Dokumentation.Danke für deine Zeit und den Input. Ich habe erst mal einige Dinge zum testen und umsetzen.
Sicherlich kommen irgendwann noch ein paar Rückfragen, möchte mich zum lernen aber erst mal durchbeißen und schauen wie weit ich komme :=)Nochmals: DANKE!
