ioBroker Docker - InfluxDB Error bei hoher Disk I/O
-
@hennerich sagte in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
Wo genau muss ich nachschauen und worauf soll ich achten?
Also bei mir (Docker+Portainer) kann ich auf die Container Logs schauen, da steht dann sowas drin:
ts=2023-05-26T20:26:23.033009Z lvl=info msg="Snapshot for path written" log_id=0i2HUNW0000 service=storage-engine engine=tsm1 op_name=tsm1_cache_snapshot path=/var/lib/influxdb2/engine/data/2b42fccaf44c370d/autogen/2747 duration=218.588ms ts=2023-05-26T20:26:23.033067Z lvl=info msg="Cache snapshot (end)" log_id=0i2HUNW0000 service=storage-engine engine=tsm1 op_name=tsm1_cache_snapshot op_event=end op_elapsed=218.661ms ts=2023-05-26T20:27:51.815523Z lvl=info msg="Retention policy deletion check (start)" log_id=0i2HUNW0000 service=retention op_name=retention_delete_check op_event=start ts=2023-05-26T20:27:51.816432Z lvl=info msg="Retention policy deletion check (end)" log_id=0i2HUNW0000 service=retention op_name=retention_delete_check op_event=end op_elapsed=0.947ms ts=2023-05-26T20:35:02.035245Z lvl=info msg="TSI log compaction (start)" log_id=0i2HUNW0000 service=storage-engine index=tsi tsi1_partition=1 op_name=tsi1_compact_log_file tsi1_log_file_id=3 op_event=start ts=2023-05-26T20:35:02.051768Z lvl=info msg="Log file compacted" log_id=0i2HUNW0000 service=storage-engine index=tsi tsi1_partition=1 op_name=tsi1_compact_log_file tsi1_log_file_id=3 elapsed=16ms bytes=1833 kb_per_sec=108 ts=2023-05-26T20:35:02.052216Z lvl=info msg="TSI log compaction (end)" log_id=0i2HUNW0000 service=storage-engine index=tsi tsi1_partition=1 op_name=tsi1_compact_log_file tsi1_log_file_id=3 op_event=end op_elapsed=17.005msKeine Ahnung, wie das bei dir aussieht. Die Idee war, dass man in diese Logs schaut, wenn die Timeouts auftreten, um zu sehen, was die DB in dieser Zeit macht.
Die 120 Sekunden finde ich ziemlich lang. Im Extremfall können dann 2min Daten verloren gehen. In den Konfigurationsbeispielen, die man so findet ist ja eher von Millisekunden die Rede.
-
@hennerich sagte in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
Wo genau muss ich nachschauen und worauf soll ich achten?
Moin,
nur als Beispiel, da ich keine
influxDBauf meiner Syno als Docker habe, aber wenn Du auf der Syno Standard-Docker ohne Portainer nutzt, dann sollten die Logs hier einsehbar sein.Beispiel:
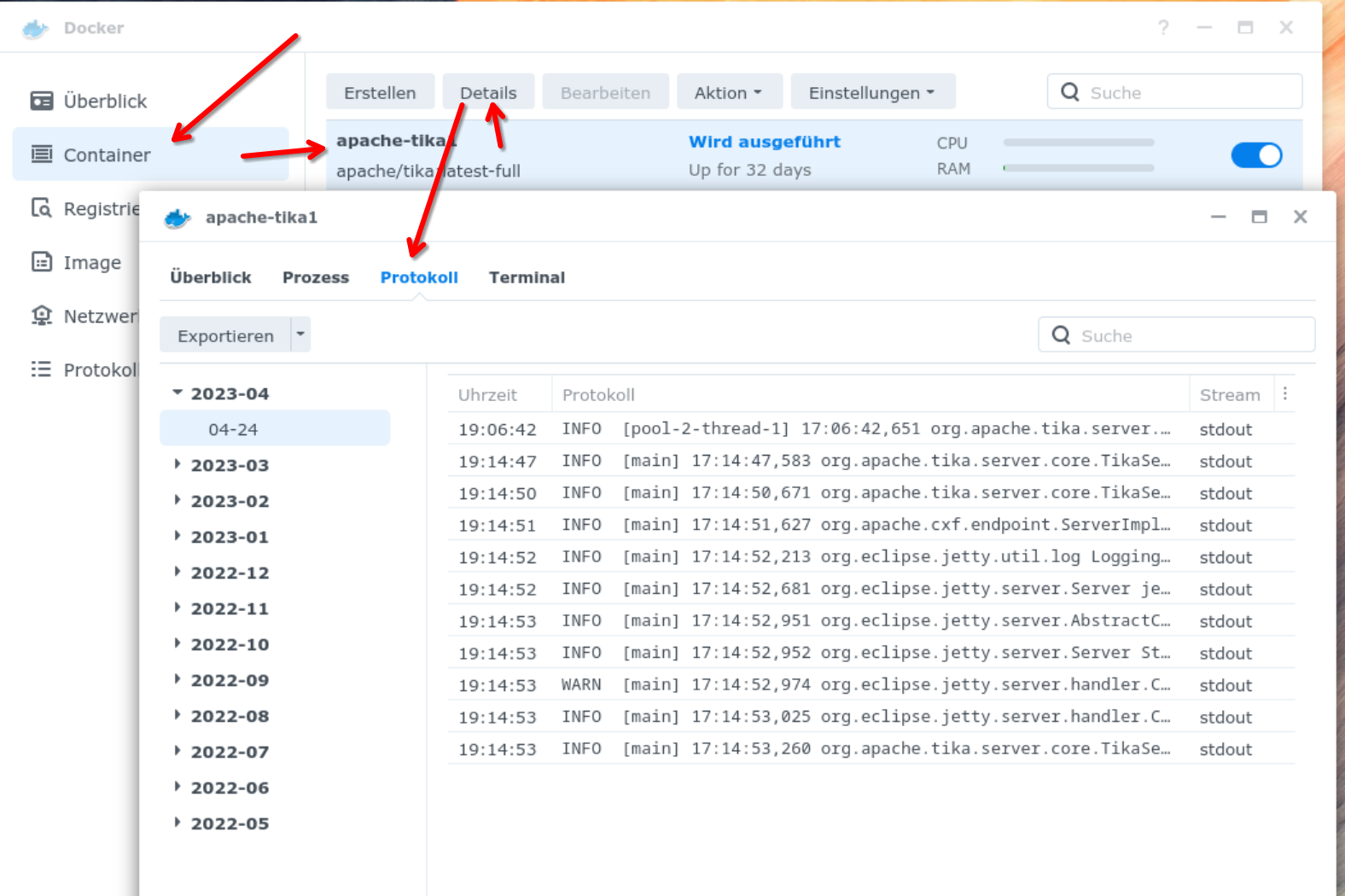
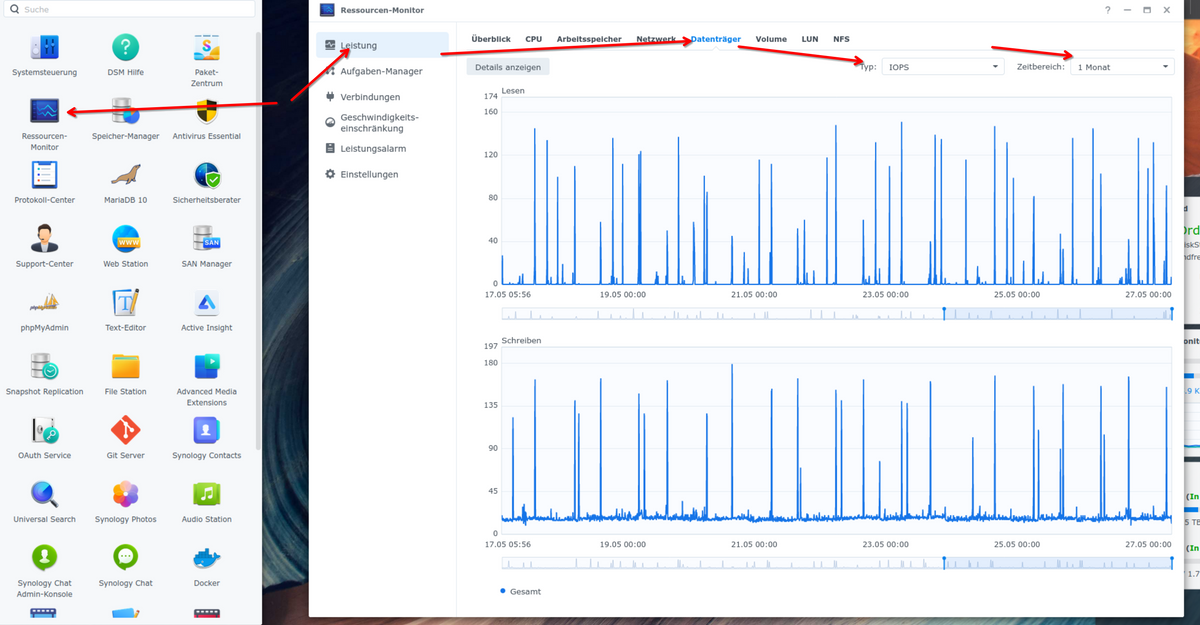
Du kannst auch mal im Ressourcenmonitor der Syno schauen, ob da etwas auffälliges zu sehen ist
VG
Bernd -
Hey, danke für eure Ideen.
Ich hab auch Portainer und kann in die Logs schauen.
Nur hab ich davon keine Ahnung. Sowas steht da drin:
Seit gestern ist das ioBroker Log auf knapp 1GB angewachsen. Ich restarte jetzt den Adapter und lösche das Log.
Dann schauen wir mal, ob die 120s etwas gebracht haben. -
Update: als ich den Adapter neu gestartet habe, sind die Meldungen direkt wieder aufgetreten.
Ich kann nur vermuten, dass das an den 120s gelegen hat, denn nachdem ich den Wert zurück auf 0s (default) gestellt hatte, waren die Fehler wieder weg. -
@hennerich sagte in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
Update: als ich den Adapter neu gestartet habe, sind die Meldungen direkt wieder aufgetreten.
Ich kann nur vermuten, dass das an den 120s gelegen hat, denn nachdem ich den Wert zurück auf 0s (default) gestellt hatte, waren die Fehler wieder weg.Moin,
wie @Marc-Berg schon gesagt hat, 120s sind zu viel, denn als Standard ist 0, und in den Beispielen sind es
msalso wenn Du mit diesem Parameter spielen möchtest, dann eher immsBereich und nicht imsek.Bereich.Erklärung des Parameters https://docs.influxdata.com/influxdb/v2.7/reference/config-options/#influxd-flag-47
storage-wal-fsync-delay Duration a write will wait before fsyncing. A duration greater than 0 batches multiple fsync calls. This is useful for slower disks or when WAL write contention is present.Vielleicht ist das der bessere Wert, den Du anpassen kannst, Standard sind
10 sek.da kannst Du ja mal in Fünfer Schritten, die Zeit anpassen,INFLUXD_STORAGE_WRITE_TIMEOUTstorage-write-timeout Maximum amount of time the storage engine will process a write request before timing out.VG
Bernd -
Danke Bernd, hab ich eingestellt.
Du sag mal, wo genau in der Influx Doku hast du den denn gefunden? Wenn ich nach dem Parameter in Google suche, finde ich nicht wirklich was.[Edit]
Habs gefunden: https://docs.influxdata.com/influxdb/v2.7/reference/config-options/#storage-write-timeout -
@hennerich sagte in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
Danke Bernd, hab ich eingestellt.
Du sag mal, wo genau in der Influx Doku hast du den denn gefunden? Wenn ich nach dem Parameter in Google suche, finde ich nicht wirklich was.Moin,
ich stöber immer beim Hersteller selbst
")
Das ist die Einstiegsseite https://docs.influxdata.com/influxdb/v2.7/# und dann entweder in der Suche oben links.
Das ist die Seite mit den Optionen https://docs.influxdata.com/influxdb/v2.7/reference/config-options/#VG
Bernd -
kleines Zwischenfazit: heute Nacht war alles gut, kein Anstieg zu verzeichnen
Mal schauen wie sich das die nächsten Tage verhält -
So, ich hatte zwar zwischendrin (irgendwann mal im Laufe des Tages) wieder einen Vorfall, aber bis jetzt scheint es Nachts nach der Sicherung immer zu funktionieren.
-
@hennerich sagte in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
So, ich hatte zwar zwischendrin (irgendwann mal im Laufe des Tages) wieder einen Vorfall,
Moin,
erst einmal schön, dass es bei Dir jetzt etwas ruhiger zugeht und alles so weit funktioniert.
Wenn es passieren solltest, Du mal schauen, was Du gerade gemacht hast, am/im System und/oder schauen, was da die DiskStation gerade gemacht hat, vielleicht lief da gerade ein aufwändiger Task.
VG
Bernd -
@glasfaser said in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
Ich kenne deine Grundeinstellungen in der Influx Instanz nicht ,
du könntest versuchen die Schreibaktionen zu sammeln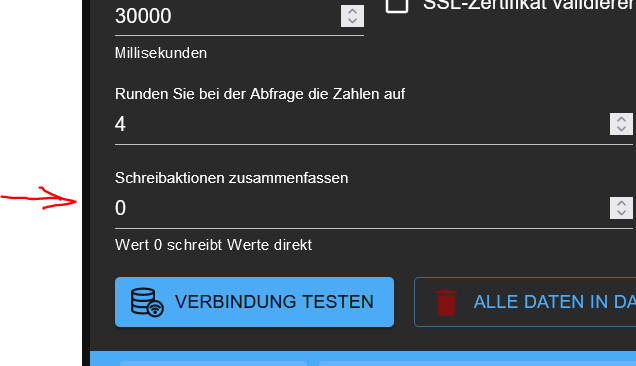
sie werden dann zwischengespeichert und einmalig von Influx in der eingestellten Zeit versendet .
Nachteil , sollte etwas in der Zwischenspeicherung / Zeit passieren , sind die Daten weg .
Bedenke .. Hyper Backup braucht viel Leistung , habe daher die Zeiten ( mehere Regeln ) versetzt eingestellt
Danke für diesen Tipp. Ich bin in den letzten Wochen ebenfalls mit dem oben beschriebenen Problem konfrontiert worden.
Habe nun versuchsweise die Schreibaktionen zusammenfassen auf 5 gestellt. Der Fehler tritt nicht mehr auf. Nun habe ich es seit drei Tagen auf 2 eingestellt, ebenfalls keine Fehlermeldungen mehr bis jetzt. -
zu früh gefreut, der Fehler / das Problem tritt bei mir wieder auf...
-
@rikdrs sagte in ioBroker Docker - InfluxDB Error bei hoher Disk I/O:
zu früh gefreut, der Fehler / das Problem tritt bei mir wieder auf...
Das hätte mich auch gewundert, da die vermeintliche Lösung am Problem vorbei geht. Dies besteht aus meiner Sicht darin, dass die InfluxDB regelmäßig Aufräum ("Compactions")-Arbeiten durchführt. Diese sind durch eine sehr starke I/O-Last erkennbar. Wenn das Verhältnis (Menge der Daten / Leistungsfähigkeit der Hardware) zu schlecht wird, laufen diese Jobs extrem lang, in dieser Zeit sind Write-Errors zu beobachten.
Du könntest zum einen versuchen, die Anzahl der "Concurrent compactions" auf "1" zu setzen.
Wesentlich erfolgversprechender ist es aber, die Menge an Daten radikal zu reduzieren. Schau mal, wo die meisten herkommen:
from(bucket: "iobroker") |> range(start: -10y) |> filter(fn: (r) => r["_field"] == "value") |> count() |> group() |> keep(columns: ["_measurement", "_value"]) |> sort(columns: ["_value"], desc: true) |> rename(columns: {_value: "Anzahl"})
