[gelöst] Fehler beim schreiben auf influxdb
-
@homoran sagte in Fehler beim schreiben auf influxdb:
Beim nächsten Mal musst du ihn sonst auswendig lernen!


VG
Bernd -
@ben1983 sagte in Fehler beim schreiben auf influxdb:
Auf Grafana sind alle Daten da. Also er schreibt sie wohl.
Moin,
wenn Dein System, auf dem die Docker laufen, ausgelastet ist, dann kann es sein, dass die Daten nicht schnell genug abgenommen werden, dann bekommt es zu diesen Timeouts.
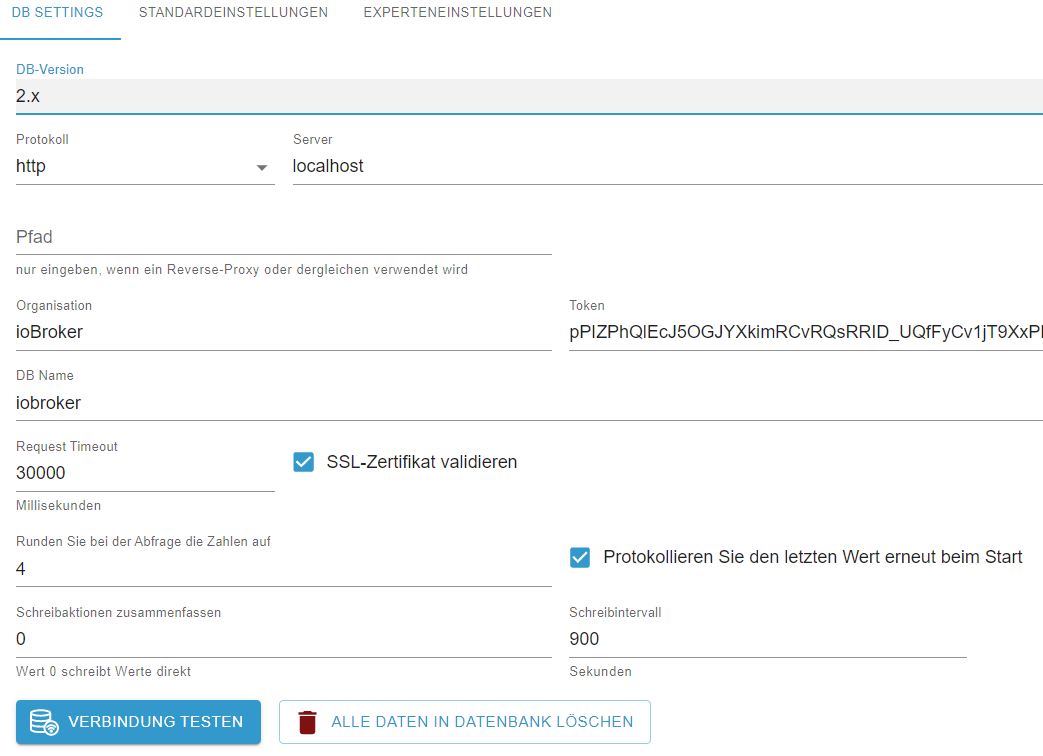
Wie sieht denn die Konfiguration des
influxDB Adaptersaus, Du könntest dort ein paar Daten sammeln, bevor Du sie wegschreibst.
Und wie sieht denn die Docker Konfiguration, CPU, RAM aus?
VG
Bernd -
@dp20eic
sowas müsste dann auch in den logs sichtbar sein
-> applikationslog (hier influxdb)
-> syslog des containers
-> syslog des hostsystems -
@dp20eic
-
@ben1983
ah ich sehe influx hat mit http 500 geantwortet.
d.h. irgendwas ist bei influx schief gegangen.
da musst du auf jeden fall ins applikationslog von influx schauen.
https://docs.influxdata.com/influxdb/v2.7/admin/logs/der timeout bedeutet nur, das iobroker nicht innerhalb einer bestimmten zeit geantwortet hat, was influx nicht konnte, wegen unvorhergesehenem abbruch
-
@ben1983 sagte in Fehler beim schreiben auf influxdb:
@dp20eic
Moin,
wirklich nur 108 MB RAM, oder der ohne Begrenzung, nur aktuell verbraucht
influxDBnicht mehr?InfluxDB OSS guidelines Run InfluxDB on locally attached solid state drives (SSDs). Other storage configurations have lower performance and may not be able to recover from small interruptions in normal processing. Estimated guidelines include writes per second, queries per second, and number of unique series, CPU, RAM, and IOPS (input/output operations per second).vCPU or CPU RAM IOPS Writes per second Queries* per second Unique series 2-4 cores 2-4 GB 500 < 5,000 < 5 < 100,000 4-6 cores 8-32 GB 500-1000 < 250,000 < 25 < 1,000,000 8+ cores 32+ GB 1000+ > 250,000 > 25 > 1,000,000 Nur so als Hinweis,
influxDBInfluxDB InfluxDB is a dedicated time series database that borrows many design concepts from **in-memory** databases to improve **write** and **query** performance for time series data specifically. InfluxDB can be configured to use different amounts of memory, write to flash memory for hybrid storage architectures, and writes data to disk using an append-only log to get performance similar to in-memory databases.Wenn bei Dir viele Schreibzugriffe und dann noch Abfragen, z.B. durch Grafana aufeinander treffen, dann ist Speicher gefragt, bin kein Docker Experte, daher kann das, was ich schreibe, auch Quatsch sein, kenne nicht die Mechanismen nicht wie Docker Memory on the Fly zuteilt, ob das schnell genug ist.
Was ich damit eigentlich sagen wollte, vielleicht ist es besser deminfluxDBDocker feste Werte zuzuweisen.Und wie @OliverIO schrieb, mal die Logs auf dem
influxDBDocker durchschauen, was da evtl. geklemmt hat.VG
Bernd -
@dp20eic
Starting precreation service {"log_id": "0hvKzKT0000", "service": "shard-precreation", "check_interval": "10m", "advance_period": "30m"} 2023-05-20T13:21:09.048393Z info Starting query controller {"log_id": "0hvKzKT0000", "service": "storage-reads", "concurrency_quota": 1024, "initial_memory_bytes_quota_per_query": 9223372036854775807, "memory_bytes_quota_per_query": 9223372036854775807, "max_memory_bytes": 0, "queue_size": 1024} 2023-05-20T13:21:09.054059Z info Configuring InfluxQL statement executor (zeros indicate unlimited). {"log_id": "0hvKzKT0000", "max_select_point": 0, "max_select_series": 0, "max_select_buckets": 0} 2023-05-20T13:21:10.249818Z info Starting {"log_id": "0hvKzKT0000", "service": "telemetry", "interval": "8h"} 2023-05-20T13:21:10.250071Z info Listening {"log_id": "0hvKzKT0000", "service": "tcp-listener", "transport": "http", "addr": ":8086", "port": 8086} 2023-05-20T13:30:14.998921Z warn internal error not returned to client {"log_id": "0hvKzKT0000", "handler": "error_logger", "error": "context canceled"} 2023-05-20T13:30:35.214408Z warn internal error not returned to client {"log_id": "0hvKzKT0000", "handler": "error_logger", "error": "context canceled"} 2023-05-20T13:31:09.047847Z info Cache snapshot (start) {"log_id": "0hvKzKT0000", "service": "storage-engine", "engine": "tsm1", "op_name": "tsm1_cache_snapshot", "op_event": "start"} 2023-05-20T13:31:09.637562Z info Snapshot for path written {"log_id": "0hvKzKT0000", "service": "storage-engine", "engine": "tsm1", "op_name": "tsm1_cache_snapshot", "path": "/var/lib/influxdb2/engine/data/7218bd3b5168e452/autogen/6", "duration": "589.695ms"} 2023-05-20T13:31:09.637615Z info Cache snapshot (end) {"log_id": "0hvKzKT0000", "service": "storage-engine", "engine": "tsm1", "op_name": "tsm1_cache_snapshot", "op_event": "end", "op_elapsed": "589.775ms"} -
@dp20eic der Verbraucht gerade nur 108MB. Ist unbegrenzt
-
jetzt braucht man nur noch den richtigen zeitpunkt
2023-05-20 15:07:26.817 -
@oliverio sagte in Fehler beim schreiben auf influxdb:
jetzt braucht man nur noch den richtigen zeitpunkt
2023-05-20 15:07:26.817Moin,
ist UTC 2023-05-20T13:31:09.637615Z + 2 sollte dann 15:31Uhr
VG
Bernd -
@dp20eic
dann startet es 15:21
wir benötigen aber 15:07
also das vorgänger log wahrscheinlich,
je nachdem wie oft neugestartet wurdefalls da auch nicht viel drin steht, dann das loglevel erhöhen, sollte aber schon
-
@ben1983 sagte in Fehler beim schreiben auf influxdb:
2023-05-20T13:30:14.998921Z warn internal error not returned to client {"log_id": "0hvKzKT0000", "handler": "error_logger", "error": "context canceled"}
2023-05-20T13:30:35.214408Z warn internal error not returned to client {"log_id": "0hvKzKT0000", "handler": "error_logger", "error": "context canceled"}Moin,
schau mal hier https://community.influxdata.com/t/execution-of-heavy-queries-result-in-a-crash/22637 da steht einiges, lese aber auch erst noch.
VG
Bernd -
Opened file {"log_id": "0hvK92MG000", "service": "storage-engine", "engine": "tsm1", "service": "filestore", "path": "/var/lib/influxdb2/engine/data/1bb9099d3b7c3e2b/autogen/4/000000007-000000002.tsm", "id": 0, "duration": "10.483ms"} 2023-05-20T13:06:39.732140Z info Opened shard {"log_id": "0hvK92MG000", "service": "storage-engine", "service": "store", "op_name": "tsdb_open", "index_version": "tsi1", "path": "/var/lib/influxdb2/engine/data/1bb9099d3b7c3e2b/autogen/4", "duration": "1615.077ms"} 2023-05-20T13:06:40.087887Z info loading changes (end) {"log_id": "0hvK92MG000", "service": "storage-engine", "engine": "tsm1", "op_name": "field indices", "op_event": "end", "op_elapsed": "899.816ms"} 2023-05-20T13:06:40.088551Z info Reading file {"log_id": "0hvK92MG000", "service": "storage-engine", "engine": "tsm1", "service": "cacheloader", "path": "/var/lib/influxdb2/engine/wal/7218bd3b5168e452/autogen/6/_00001.wal", "size": 1359140} 2023-05-20T13:06:40.675328Z info Opened shard {"log_id": "0hvK92MG000", "service": "storage-engine", "service": "store", "op_name": "tsdb_open", "index_version": "tsi1", "path": "/var/lib/influxdb2/engine/data/7218bd3b5168e452/autogen/6", "duration": "1510.816ms"} 2023-05-20T13:06:40.675775Z info Open store (end) {"log_id": "0hvK92MG000", "service": "storage-engine", "service": "store", "op_name": "tsdb_open", "op_event": "end", "op_elapsed": "4409.592ms"} 2023-05-20T13:06:40.675870Z info Starting retention policy enforcement service {"log_id": "0hvK92MG000", "service": "retention", "check_interval": "30m"} 2023-05-20T13:06:40.675935Z info Starting precreation service {"log_id": "0hvK92MG000", "service": "shard-precreation", "check_interval": "10m", "advance_period": "30m"} 2023-05-20T13:06:40.677588Z info Starting query controller {"log_id": "0hvK92MG000", "service": "storage-reads", "concurrency_quota": 1024, "initial_memory_bytes_quota_per_query": 9223372036854775807, "memory_bytes_quota_per_query": 9223372036854775807, "max_memory_bytes": 0, "queue_size": 1024} 2023-05-20T13:06:40.682348Z info Configuring InfluxQL statement executor (zeros indicate unlimited). {"log_id": "0hvK92MG000", "max_select_point": 0, "max_select_series": 0, "max_select_buckets": 0} 2023-05-20T13:06:42.173468Z info Starting {"log_id": "0hvK92MG000", "service": "telemetry", "interval": "8h"} 2023-05-20T13:06:42.218552Z info Listening {"log_id": "0hvK92MG000", "service": "tcp-listener", "transport": "http", "addr": ":8086", "port": 8086} 2023-05-20T13:20:43.289848Z warn internal error not returned to client {"log_id": "0hvK92MG000", "handler": "error_logger", "error": "context canceled"} 2023-05-20T13:20:43.296515Z warn internal error not returned to client {"log_id": "0hvK92MG000", "handler": "error_logger", "error": "context canceled"} -
kannst du bitte mal schauen ob die uhren in beiden containern gleich laufen? also die minuten reichen aus.
das warn internal error not returned könnte passen, aber die zeit passt nicht. da ist der unterschied zu groß
hab auch ein issue gefunden der passen könnte
https://github.com/influxdata/influxdb/issues/24055
allerdings geht es da um große datenmengen.
das schreiben eines datenpunkts ist jetzt wirklich kein großer act
daher könnte es schon sein, das genau zu diesem zeitpunkt die hostmaschine gut ausgelastet ist.
wann läuft dein backup von iobroker oder eines anderen containers?aber du kannst mal schauen ob man am adapter irgendwo den timeout anpassen kann.
-
@oliverio sagte in Fehler beim schreiben auf influxdb:
kannst du bitte mal schauen ob die uhren in beiden containern gleich laufen? also die minuten reichen aus.
wie genau mache ich das?
")
Das Backup läuft nachts um 3 Uhr. Also daran kann es nicht gelegen haben.
-
docker oder portainer?
shell öffnen und dann den date befehl ausführen
shell öffnen mit docker:
docker exec -it <container name> /bin/bashshell öffnen mit portainer
den container auswählen und dann link zu console
und console öffnen -
@ben1983 sagte in Fehler beim schreiben auf influxdb:
Das Backup läuft nachts um 3 Uhr. Also daran kann es nicht gelegen haben
nachts oder nachmittags? am oder pm
der Fehler trat 15:07 auf -
ich dachte ich habe es schon geschrieben, was du auch noch untersuchen kannst:
ist es immer um die ähnliche uhrzeit wo der fehler auftritt?
ggfs. musst du mal eine kontinuierliche leistungsaufzeichnung starten.
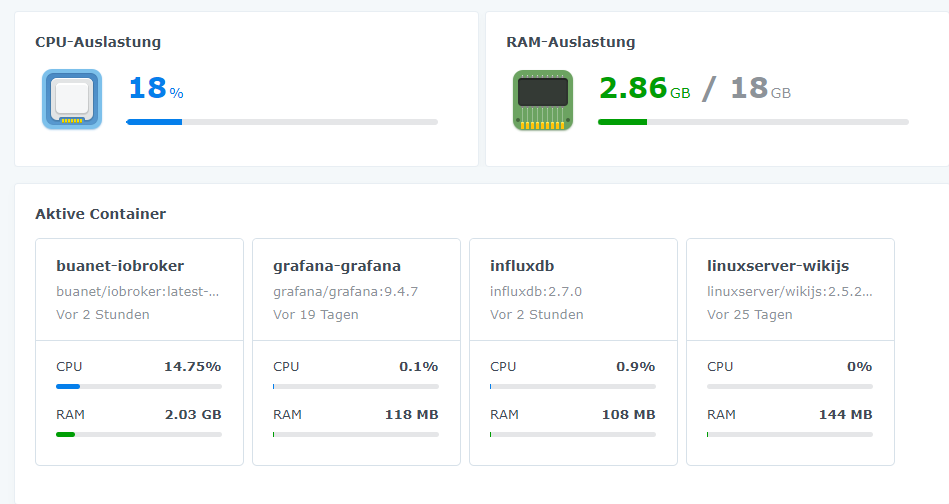
dein screenshot ist ja nur eine momentaufnahme und zeigt bspw nicht die auslastung zu höchstzeiten an.
auch kannst mal deine skripte prüfen, ob es da welche gibt die um die besagten uhrzeiten irgendwas größeres machen. kann ja auch ein skriptfehler sein, der die ressourcen (cpu, ram, netzkapazität) überbeansprucht auch wenn scheinbar genug da sind.
oder auch bspw ein jdownloader der cpu und/oder netz zumacht -
@oliverio Es war heute das erste mal .... es läuft seit ca. 7 Wochen
-
dann weiter beobachten.
aber das mit der uhrzeit noch prüfen, damit man in zukunft nicht nochmal suchen muss

