Skript zum Downsamplen einer Influx 2.x DB
-
Hallo, ich hab mir ein kleines Skript geschrieben das mir die InfluxDB 2.x Datenbank in der die History gespeichert wird rückwirkend zusammenfasst. Hat bei mir mit normalen Querys nicht geklappt. Daher falls es jemanden gebrauchen kann:
Task dazu muss am besten vorher erstellt werden:
/* Script fasst Daten in einer Influx 2.x Datenbank zusammen. Nummernwerte werden als mean() abgespeichert. Sowie mit Tag und als max, min Alle anderen Typen als last() Bei Abbruch warten das die Meldung gestoppt im Log erscheint, der letzten Aufruf wird abgearbeitet. Die einzelne Gruppe werden im Abstand von Delay bearbeitet. Eine Gruppe besteht aus einer ID und einem Zeitfenster von 10 Tagen // je nach Anzahl der Werte kann das alles etwas dauern. 300 States 30 Tage ca. ne Stunde ******* Task ******** import "types" option task = {name: "1m_iobroker", every: 1m, offset: 2m} data = from(bucket: "iobroker") |> range(start: -2m) |> filter(fn: (r) => r["_field"] == "value") data |> filter( fn: (r) => types.isType(v: r._value, type: "int") or types.isType(v: r._value, type: "float") or types.isType(v: r._value, type: "uint"), ) |> aggregateWindow(every: 1m, fn: mean, createEmpty: false) |> to(bucket: "1m_iobroker", org: "org") data |> filter( fn: (r) => types.isType(v: r._value, type: "int") or types.isType(v: r._value, type: "float") or types.isType(v: r._value, type: "uint"), ) |> aggregateWindow(every: 1m, fn: min, createEmpty: false) |> set(key: "agg_type", value: "min") |> to(bucket: "1m_iobroker", org: "org") data |> filter( fn: (r) => types.isType(v: r._value, type: "int") or types.isType(v: r._value, type: "float") or types.isType(v: r._value, type: "uint"), ) |> aggregateWindow(every: 1m, fn: max, createEmpty: false) |> set(key: "agg_type", value: "max") |> to(bucket: "1m_iobroker", org: "org") data |> filter( fn: (r) => types.isType(v: r._value, type: "int") == false and types.isType( v: r._value, type: "float", ) == false and types.isType(v: r._value, type: "uint") == false, ) |> aggregateWindow(every: 1m, fn: last, createEmpty: false) |> to(bucket: "1m_iobroker", org: "org") ******* Task Ende *********+ */ // die Influxdb instance die verwendenw ird const instanze = 'influxdb.1' // Zeitraum der zusammengefasst werden soll. Beispiele: 1d, 1h, 10m const aggreagteWindow = '1m' const start = 90 // Tag rückwärts an dem es starten soll. const sourceBucket = 'iobroker' // von da const targetBucket = '1m_iobroker' // nach hier const org = 'org' // organisation var index = 1 // bei einem Abbruch hier die Nummer eintragen Default: 01 const delay = 100 // delay zwischen den ID und den Zeiträumen // Finger weg var r // result var k = null// keys const imports = 'import "types" import "strings" ' const part1p = 'data = from(bucket: "' + sourceBucket + '") |> range(start: -' const fluxP2 = 'd) |> filter(fn: (r) => r["_field"] == "value") |> filter(fn: (r) => r["_measurement"] == "' // mean ohne Tag kompalibel zu Realtimedaten Grafana const fluxAnMean = '") data |> aggregateWindow(every: ' + aggreagteWindow + ', fn: mean, createEmpty: false) |> to(bucket: "' + targetBucket + '", org: "'+org+'") ' // alternative mean mit Tags //const fluxAnMean = '") data |> aggregateWindow(every: ' + aggreagteWindow + ', fn: mean, createEmpty: false) |> set(key: "agg_type", value: "mean") |> to(bucket: "' + targetBucket + '", org: "'+org+'") ' const fluxAnMin = '") data |> aggregateWindow(every: ' + aggreagteWindow + ', fn: max, createEmpty: false) |> set(key: "agg_type", value: "max") |> to(bucket: "' + targetBucket + '", org: "'+org+'") ' const fluxAnMax = '") data |> aggregateWindow(every: ' + aggreagteWindow + ', fn: min, createEmpty: false) |> set(key: "agg_type", value: "min") |> to(bucket: "' + targetBucket + '", org: "'+org+'") ' const fluxAs = '") data |> aggregateWindow(every: ' + aggreagteWindow + ', fn: last, createEmpty: false) |> to(bucket: "' + targetBucket + '", org: "'+org+'")' const fluxP = imports + part1p var onStopped = false; var counter =index/ 10; var b = 0 index = index-1 sendTo(instanze, 'getEnabledDPs', {}, function (result) { if (!result || result === undefined) { log(JSON.stringify(result)) log('Fehler im Rückgabewert 2') return } k = Object.keys(result) if (!k.length) return for (let b = 0; b < k.length; b++) { if (!result[k[b]].enabled) { k.splice(b--, 1) continue } } if (!k.length) { log('Keine IDs gefunden') return } log('Starte Downsampling') doTheWork() log(k[index] + ' (' +(index+1)+'/'+(k.length) + ') start') }); function doTheWork() { b++ if ( b>=start/10+1) { log(k[index] + ' (' +(index+1)+'/'+(k.length) + ') done') b = 1 index++ if (index < k.length) log(k[index] + ' (' +(index+1)+'/'+(k.length) + ') start') } let s = (b-1)*10 let end = (b * 10)+1 if (end > start) end = start if (index >= k.length) { log('Downsampling beendet') return } //log(index+1+'/'+(k.length)+' Downsampling von ID: ' + k[index] + ' start: -' + end + 'd end: -' + s + 'd' ) let o = getObject(k[index]) if (o.common.type === 'number') { let q1 = fluxP + end + 'd , stop: -'+ s + fluxP2 + k[index] + fluxAnMean // erstelle die CQ sendTo(instanze, 'query', q1 , function (result) { if (result.error) { console.error(result.error); } else { //if (result.result.length) log(result.result[0][0]) q1 = fluxP + end + 'd , stop: -'+ s + fluxP2 + k[index] + fluxAnMin sendTo(instanze, 'query', q1 , function (result) { if (result.error) { console.error(result.error); } else { //if (result.result.length) log(result.result[0][0]) q1 = fluxP + end + 'd , stop: -'+ s + fluxP2 + k[index] + fluxAnMax sendTo(instanze, 'query', q1 , function (result) { if (result.error) { console.error(result.error); } else { //if (result.result.length) log(result.result[0][0]) doWork() } }) } }) } }) } else { let q1 = fluxP + end + ', stop: -'+ s + fluxP2 + k[index] + fluxAs // erstelle die CQ //log(q1) sendTo(instanze, 'query', q1 , function (result) { if (result.error) { console.error(result.error); } else { //if (result.result.length) log(result.result[0][0]) doWork() } }) } } onStop(function (callback) { onStopped = true; callback() },2000) // starte nächsten Durchlauf nach delay function doWork() { if (onStopped) { log('gestoppt!') return } setTimeout(doTheWork, delay) }Edit: noch einen kleinen Fehler behoben der bei der letzten done Meldung auftritt
-
@ticaki Hallo, vielleicht kannst Du mir kurz helfen:
Ich verwende folgende Task um Daten aus der aktiven Datenbank zu komprimieren. Iobroker hat ja immer einen Datenpunkt als measurement. Nun würde ich gerne in meiner Zieldatenbank ein neues measurement energy anlegen und darunter mehrere fields exportedWh, importedWh anlegen.
Hiermit habe ich getestet:
import "date" option task = {name: "0_move_tmp", every: 1y} fullHourTime = date.truncate(t: now(), unit: 1h) from(bucket: "iobroker-data") |> range(start: 2023-01-01T00:00:00Z, stop: fullHourTime) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out") |> filter(fn: (r) => r["_field"] == "value") |> filter(fn: (r) => r._value > 0) |> difference() |> aggregateWindow(every: 15m, fn: sum, createEmpty: true) |> to(bucket: "testdb", fieldFn: (r) => ({"exportedWh": r._value}))Folgendes ist das Resultat:
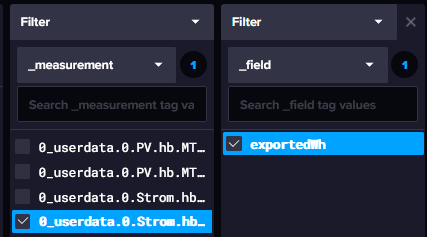
Nun meine Frage: Was muss ich bei
|> to(bucket: "testdb", fieldFn: (r) => ({"exportedWh": r._value}))anpassen/ergänzen, damit ich ein neues measurement energy erhalte?
Danke im Voraus!
-
@manrum1 sagte in Skript zum Downsamplen einer Influx 2.x DB:
Danke im Voraus
Moin,
ob es passt, oder ob es gut gelöst ist, lassen wir mal dahingestellt
")
import "timezone" option location = timezone.location(name: "Europe/Berlin") option task = {name: "Downsampling Vb_Stromzaehler", cron: "15 0 * * *"} data = from(bucket: "iobroker_strom") |> range(start: -1y, stop: now()) |> filter(fn: (r) => r["_measurement"] == "sonoff.0.DVES_8AA766.SENSOR.SML.total_kwh") |> filter(fn: (r) => r["_field"] == "value") // Spalten "_start", "_stop", "ack", "from", "q", ausschliessen |> drop(columns: ["ack", "q", "from"]) data |> aggregateWindow(every: 1d, fn: last, timeSrc: "_time") // In Wh ohne Komma |> toInt() |> set(key: "_measurement", value: "Hauptzaehler") // Use the to() function to validate that the results look correct. This is optional. |> to(bucket: "Stromverbrauch", org: "iobroker_strom")VG
Bernd -
@dp20eic said in Skript zum Downsamplen einer Influx 2.x DB:
|> set(key: "_measurement", value: "Hauptzaehler")
Super! Danke, habe wie folgt angepasst und es funktioniert!
import "date" option task = {name: "0_move_tmp", every: 1y} fullHourTime = date.truncate(t: now(), unit: 1h) from(bucket: "iobroker-data") |> range(start: 2023-01-01T00:00:00Z, stop: fullHourTime) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out") |> filter(fn: (r) => r["_field"] == "value") |> filter(fn: (r) => r._value > 0) |> difference() |> aggregateWindow(every: 15m, fn: sum, createEmpty: true) |> set(key: "_measurement", value: "energy") |> to(bucket: "testdb", fieldFn: (r) => ({"exportedWh": r._value})) -
Oben hattest du noch geschreiben, dass du "mehrere fields exportedWh, importedWh" in einem Measurement haben willst. Gibt es denn noch einen weiteren Datenpunkt "importedWh"?
-
@marc-berg Hi Marc,
danke, dass du dich meldest. Ja, aber dafür lege dann eine eigene Task an. Oder hast Du einen besseren Vorschlag? -
Ich weiß nicht, ob ich die Aufgabenstellung richtig verstanden habe, wenn ja, dann müsstest du "<importedWh>" durch dein MEasurement ersetzen, in welchem die Werte stehen:
import "date" option task = {name: "0_move_tmp", every: 1y} fullHourTime = date.truncate(t: now(), unit: 1h) from(bucket: "iobroker-data") |> range(start: 2023-01-01T00:00:00Z, stop: fullHourTime) |> filter(fn: (r) => (r["_measurement"] == "0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out" or r["_measurement"] == "<importedWh>") and r["_field"] == "value" and r._value > 0) |> difference() |> aggregateWindow(every: 15m, fn: sum, createEmpty: true) |> pivot(rowKey:["_time"], columnKey: ["_measurement"], valueColumn: "_value") |> to(bucket: "testdb", fieldFn: (r) => ({"exportedWh": r["0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out"], "importedWh": r["<importedWh>"]}))Im Ergebnis hast du dann ein Measurement, in welchem beide Werte als Fields enthalten sind.
-
@marc-berg Verstehe, wäre natürlich einfacher. Probiere ich morgen gleich aus!
Danke wieder einmal!!
-
@marc-berg Die Angabe des measrurements energy hat noch gefehlt, schaut jetzt so aus und funktioniert wunderbar:
import "date" option task = {name: "0_move_tmp2", every: 1y} fullHourTime = date.truncate(t: now(), unit: 1h) from(bucket: "iobroker-data") |> range(start: 2023-01-01T00:00:00Z, stop: fullHourTime) |> filter( fn: (r) => (r["_measurement"] == "0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out" or r["_measurement"] == "0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Total") and r["_field"] == "value" and r._value > 0, ) |> difference() |> aggregateWindow(every: 15m, fn: sum, createEmpty: true) |> pivot(rowKey: ["_time"], columnKey: ["_measurement"], valueColumn: "_value") |> set(key: "_measurement", value: "energy") |> to( bucket: "testdb2", fieldFn: (r) => ({ "exportedWh": r["0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out"], "totalWh": r["0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Total"], }), )Allerdings habe ich jetzt noch das Problem meines Datenverlusts (https://forum.iobroker.net/topic/62903/gelöst-backitup-und-influxdbv2/79?_=1703005510202) und das betrifft ja leider alle Daten in meiner Datenbank. Beispiel:

Bei aufsummiereten Counter sind die Daten ja in Summe nach der Verlustwoche wieder da. Hast du eine Idee, wie ich diese als Durchschnittswerte wieder auf die Vortage verteilen kann?
-
@manrum1 sagte in Skript zum Downsamplen einer Influx 2.x DB:
Hast du eine Idee, wie ich diese als Durchschnittswerte wieder auf die Vortage verteilen kann?
Nicht schön, aber pragmatisch:
- Export einer "Vorlage", den Range am besten so anpassen, dass du ein oder mehrere Werte vor und nach der Lücke erwischst:
influx query 'from(bucket:"iobroker") |> range(start: -1d) |> filter(fn: (r) => r["_measurement"] == "0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Out") |> filter(fn: (r) => r["_field"] == "value")' --raw > outputcsv.txt-
Dann hast du ein CSV ähnliches Format, in welchem du einfach Zeilen kopierst, wieder neu einfügst und die Spalten "_time" und "_value" nach Belieben anpasst und z.B. einen Wert pro Tag einfügst. Der Header muss unverändert bleiben.
-
Import der angepassten Datei über die InfluxDB WEBgui (File Upload, CSV)
EDIT: mit diesem Verfahren lassen sich bestehende Werte ändern und neue hinzufügen, aber keine Werte löschen!
EDIT2: Export korrigiert
-
@marc-berg So klappt der Import leider nicht.

Habe Header so belassen:
Result: _result Table: keys: [_start, _stop, _field, _measurement] _start:time _stop:time _field:string _measurement:string _time:time _value:float ------------------------------ ------------------------------ ---------------------- ---------------------------------------------------- ------------------------------ ---------------------------- 2023-11-26T23:00:00.000000000Z 2023-12-04T01:00:00.000000000Z value 0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Total 2023-11-26T23:00:44.812000000Z 16407.2868 2023-11-26T23:00:00.000000000Z 2023-12-04T01:00:00.000000000Z value 0_userdata.0.Strom.hb.Status.hichiHB.SM.Energy_Total 2023-11-26T23:00:46.806000000Z 16407.3246 -
@manrum1 sagte in Skript zum Downsamplen einer Influx 2.x DB:
So klappt der Import leider nicht.
sorry, habe ich schon länger nicht gemacht. Du musst den Parameter "--raw" beim Export mitgeben. Dann sieht der Aufbau der Datei anders aus. Der Rest bleibt aber gleich.
#group,false,false,true,true,false,false,true,true #datatype,string,long,dateTime:RFC3339,dateTime:RFC3339,dateTime:RFC3339,double,string,string #default,_result,,,,,,, ,result,table,_start,_stop,_time,_value,_field,_measurement ,,1,2023-12-20T11:50:19.573820995Z,2023-12-20T12:50:19.573820995Z,2023-12-20T11:54:05.709Z,6.8,value,mqtt.0.Lora.esp03.abshum
-
@marc-berg Ja, so geht's. Werde mal die wichtigsten Daten mit dieser Methode "auffüllen". Wird ne Heidenarbeit.

Danke!
