Suche Script zur Konvertierung von Unicode auf UTF-8
-
Habe als Ausgabe mal einen neuen Datenpunkt erzeugt, in den wird nun auch was geschrieben, jedoch auch unkodiert, also noch ohne Umlaute.
In den alten Ausgabepunkt konnte nichts geschrieben werden.
Weil er von OpenWB/MQTT erzeugt wurde? -
@hg6806 sagte in Suche Script zur Konvertierung von Unicode auf UTF-8:
Die Funktion läuft wohl nicht
Naja - "laufen" tut die schon. Sie bringt nur nicht das gewünschte Ergebnis

Dann halt erstmal die Holzhammer-Methode:
let result = text.replaceAll('\u00e4', 'ä'); result = result.replaceAll('\u00f6', 'ö'); result = result.replaceAll('\u00fc', 'ü'); result = result.replaceAll('\u00c4', 'Ä'); result = result.replaceAll('\u00c6', 'Ö'); result = result.replaceAll('\u00dc', 'Ü'); result = result.replaceAll('\u00df', 'ß'); return result;Edit
Natürlich könnte man das auch generisch machen und alles was mit\u00beginnt in den entsprechenden Code übersetzen.
Das dürfte aber von der Performance noch etwas ungünstiger sein. -
@hg6806 sagte in Suche Script zur Konvertierung von Unicode auf UTF-8:
In den alten Ausgabepunkt konnte nichts geschrieben werden.
Weil er von OpenWB/MQTT erzeugt wurde?In Datenpunkte die "einem Adapter gehören" schreibt man nur dann (und zwar ohne Ack-Flag), wenn der Adapter auch etwas damit anfangen kann. Also wenn er den Wert z.B. an ein Gerät übertragen soll etc.
Zum "Umformatieren" nimmt man entweder einen Alias (wenn man den Wert per Konvertierungsfunktion verarbeiten kann) oder einen eigenen DP in0_userdata.0(wenn der Wert per Script umformatiert werden muss). -
Also, Funktion sieht jetzt so aus, wie vorgegeben:
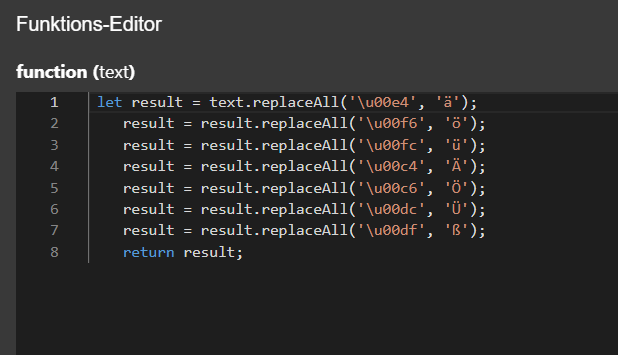
Ergebnis ist noch immer ohne Umlaute.
@Codierknecht Ja, habe jetzt den DP in userdata
-
@hg6806
Poste hier mal bitte (in Code-Tags </>) nicht das was im Log steht, sondern den Inhalt des Original-DP aus OpenWB/MQTT. -
"Ladevorgang wurde gestartet... (bei Problemen: Pr\u00fcfe bitte zuerst in den Einstellungen 'Ladeeinstellungen' und 'Konfiguration'.)" -
@hg6806
Versuchs mal so:let result = text.replaceAll('\\u00e4', 'ä'); result = result.replaceAll('\\u00f6', 'ö'); result = result.replaceAll('\\u00fc', 'ü'); result = result.replaceAll('\\u00c4', 'Ä'); result = result.replaceAll('\\u00c6', 'Ö'); result = result.replaceAll('\\u00dc', 'Ü'); result = result.replaceAll('\\u00df', 'ß'); return result; -
@codierknecht sagte in Suche Script zur Konvertierung von Unicode auf UTF-8:
let result = text.replaceAll('\u00e4', 'ä');
result = result.replaceAll('\u00f6', 'ö');
result = result.replaceAll('\u00fc', 'ü');
result = result.replaceAll('\u00c4', 'Ä');
result = result.replaceAll('\u00c6', 'Ö');
result = result.replaceAll('\u00dc', 'Ü');
result = result.replaceAll('\u00df', 'ß');
return result;BINGO!
Jetzt läuft es. Lag es evtl. an den Anführungszeichen im String?
Vielen Dank allen!
-
@hg6806 sagte in Suche Script zur Konvertierung von Unicode auf UTF-8:
Lag es evtl. an den Anführungszeichen im String?
Nein. Es lag daran, dass ein
\ein Steuerzeichen ist und im String "escaped" werden muss.Hier noch eine generische Variante:
return text.replace(/\\u[0-9a-fA-F]{4}/gi, match => { return String.fromCharCode(parseInt(match.replace(/\\u/g, ""), 16)); }); -
Ja, geht auch so. Danke nochmals!
-
@hg6806 sagte in Suche Script zur Konvertierung von Unicode auf UTF-8:
geht auch so
Dann würde ich das bevorzugen.
Die "Holzhammer-Methode" ist ja auf einige (7) spezifische Fälle beschränkt.
Die generische Variante ist universeller.
